
Aufgabenstellung
- Ein lokales LLM als KI ohne Verbindung ins Internet
- Einlesen (FineTuning) von persönlichen Dokumenten vom NAS
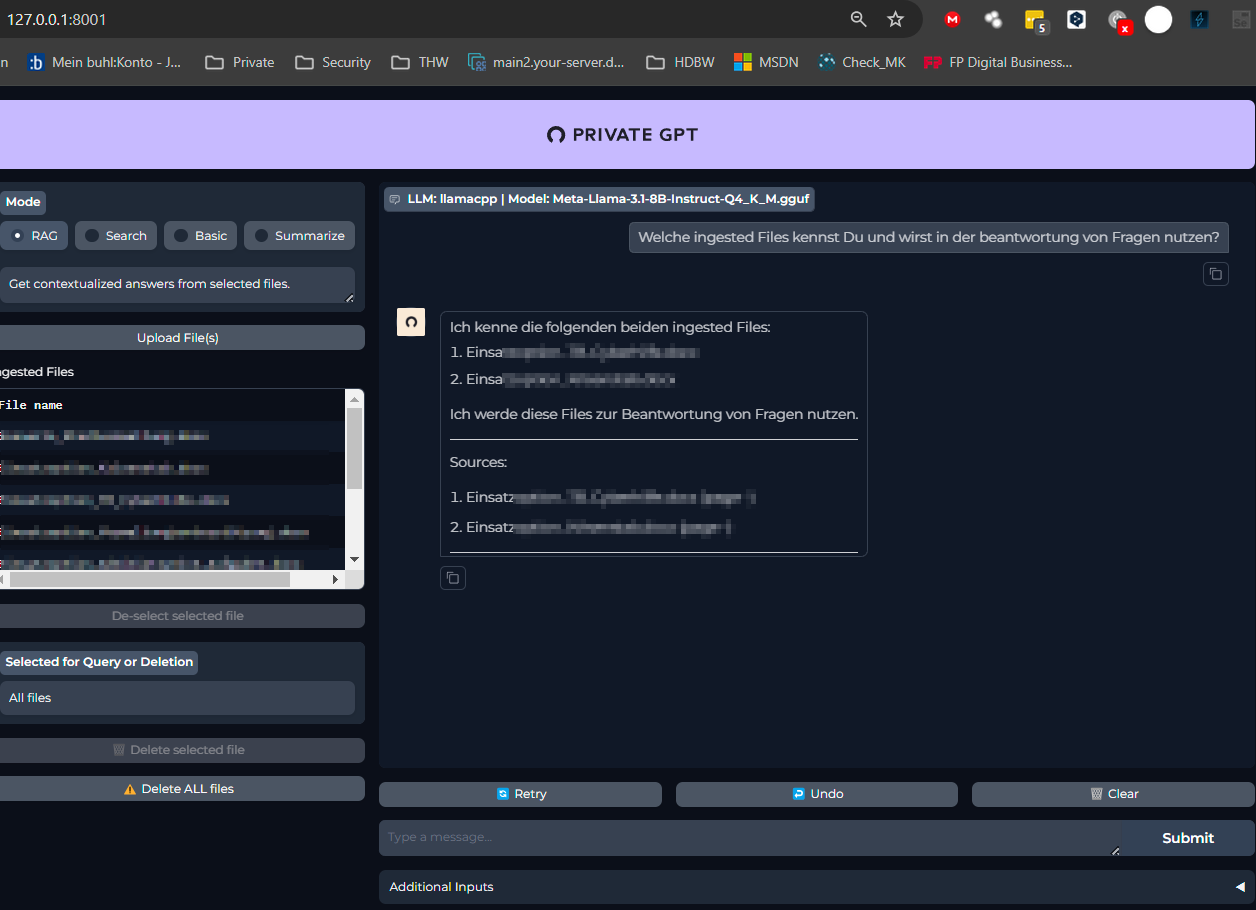
- Nutzung dieser Informationen im ChatBot
Um die Nvidia zu nutzen kommt aktuell nur eine Windowsmaschine in Frage. Dank wsl kann aber hier auf Ubuntu gesetzt werden, so dass ein favorisiertes Betriebssystem genutzt werden kann.
Es gibt ein komplettes Howto unter https://dev.to/docteurrs/installing-privategpt-on-wsl-with-gpu-support-1m2a welches alle Schritte erläutert.
Die eigentliche Quelle ist: git clone https://github.com/zylon-ai/private-gpt
Die einzigen Anpassungen die (bei mir) nötig waren:
sudo apt install nvidia-cuda-toolkit
CMAKE_ARGS='-DLLAMA_CUBLAS=OFF -DGGML_CUDA=ON' poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python
oetry install --extras ui --extras llms-llama-cpp --extras vector-stores-qdrant --extras embeddings-huggingface
Danach kann mit:
make ingest /[Quellverzeichnis]/ -- --watch --log-file ./ingest.log ein Quellverzeichnis "überwacht" werden und entsprechend die Dokumente dort eingelesen werden.
Office Support
Da im Original nicht alle Officedateien unterstützt werden, habe ich ein wenig Angepasst.
- poetry add python-pptx
- poetry add openpyxl
/private-gpt/private_gpt/components/ingest/ingest_helper.py
import logging
from pathlib import Path
from typing import List, Union
from openpyxl import load_workbook
from openpyxl.utils.exceptions import InvalidFileException
from llama_index.core.readers import StringIterableReader
from llama_index.core.readers.base import BaseReader
from llama_index.core.readers.json import JSONReader
from llama_index.core.schema import Document
logger = logging.getLogger(__name__)
# Inspired by the `llama_index.core.readers.file.base` module
def _try_loading_included_file_formats() -> dict[str, type[BaseReader]]:
try:
from llama_index.readers.file.docs import DocxReader, PDFReader # type: ignore
from llama_index.readers.file.slides import PptxReader # type: ignore
from llama_index.readers.file.tabular import PandasCSVReader # type: ignore
except ImportError as e:
raise ImportError("`llama-index-readers-file` package not found") from e
return {
".pdf": PDFReader,
".docx": DocxReader,
".pptx": PptxReader,
".csv": PandasCSVReader,
}
# Patching the default file reader to support other file types
FILE_READER_CLS = _try_loading_included_file_formats()
FILE_READER_CLS.update(
{
".json": JSONReader,
}
)
class IngestionHelper:
"""Helper class to transform a file or text into a list of documents."""
@staticmethod
def transform_file_into_documents(
file_name: str, file_data: Union[str, Path]
) -> List[Document]:
# Handle raw text
if isinstance(file_data, str) and "\n" in file_data:
logger.info("Detected raw text input; processing as text content.")
return IngestionHelper._handle_raw_text(file_data)
# Handle file paths
if isinstance(file_data, (str, Path)):
try:
file_data_path = Path(file_data).resolve(strict=True)
return IngestionHelper._load_file_to_documents(file_name, file_data_path)
except FileNotFoundError:
logger.error(f"File not found: {file_data}")
except OSError as e:
logger.error(f"Error accessing file: {file_data} - {e}")
return []
@staticmethod
def _handle_raw_text(raw_text: str) -> List[Document]:
"""Handle cases where the input is raw text instead of a file."""
string_reader = StringIterableReader()
try:
return string_reader.load_data([raw_text])
except Exception as e:
logger.error(f"Error processing raw text: {e}")
return []
@staticmethod
def _load_file_to_documents(file_name: str, file_data: Path) -> List[Document]:
logger.debug("Transforming file_name=%s into documents", file_name)
if not file_data.is_file():
logger.error(f"Path is not a file: {file_data}")
return []
extension = file_data.suffix.lower()
reader_cls = FILE_READER_CLS.get(extension)
if reader_cls is None:
logger.debug(
"No reader found for extension=%s, using default string reader",
extension,
)
try:
string_reader = StringIterableReader()
return string_reader.load_data([file_data.read_text(encoding="utf-8")])
except Exception as e:
logger.error(f"Failed to read text file {file_data}: {e}")
return []
logger.debug("Specific reader found for extension=%s", extension)
try:
documents = reader_cls().load_data(file_data)
except Exception as e:
logger.error(f"Error reading file {file_data} with extension {extension}: {e}")
documents = []
# Sanitize NUL bytes in text which can't be stored in databases
for i in range(len(documents)):
documents[i].text = documents[i].text.replace("\u0000", "")
return documents
@staticmethod
def _exclude_metadata(documents: List[Document]) -> None:
logger.debug("Excluding metadata from count=%s documents", len(documents))
for document in documents:
document.metadata["doc_id"] = document.doc_id
# We don't want the Embeddings search to receive this metadata
document.excluded_embed_metadata_keys = ["doc_id"]
# We don't want the LLM to receive these metadata in the context