
netzpolitik.org
Bitte aktualisieren Sie PHP auf Version 8.2.0 (zurzeit: 8.1.2-1ubuntu2.25). Info
Einzelne EU-Staaten dürfen Plattformen wie TikTok derzeit nicht zu Alterskontrollen verpflichten, betont die EU-Kommission. Das könnte nationale Social-Media-Verbote zur Luftnummer machen. Unter anderem Frankreich und Österreich preschen mit eigenen Gesetzen voran.

Keine soziale Medien unter 15 Jahren, darauf hat sich das französische Parlament jüngst geeinigt. Aber bei der Durchsetzung gibt es einen Haken: Frankreich darf Plattformen nicht zu Alterskontrollen verpflichten, zumindest nicht nach aktueller Rechtslage. Das betont die EU-Kommission in einer Stellungnahme vom 8. Juli, die auch auf Deutsch zu lesen ist.
Der Grund ist das EU-Gesetz über digitale Dienste (DSA), das bei der Regulierung von Plattformen Vorrang vor nationalen Gesetzen hat. So sieht der DSA nicht vor, dass einzelne Mitgliedstaaten noch strengere Pflichten für Plattformbetreiber einführen. Alterskontrollen sind laut DSA bloß eine von mehreren möglichen Maßnahmen für Plattformen, um junge Menschen besser zu schützen.
Hinzu kommt, dass Frankreich nach dem DSA für soziale Medien wie TikTok und Instagram nicht zuständig ist. Als „sehr große Plattformen“ fallen sie unter die Aufsicht der EU-Kommission.
Anlass der Stellungnahme ist das sogenannte Notifizierungsverfahren. Einfach ausgedrückt sagen Mitgliedstaaten Bescheid, welche neuen Vorschriften sie schaffen wollen. Nach einer Prüfung kann die EU-Kommission Einwände erheben, wenn sie Konflikte mit EU-Recht sieht, etwa „für den freien Verkehr von Diensten der Informationsgesellschaft“.
Stellungnahme macht Zwist sichtbar
Schon seit Monaten arbeiten EU-Staaten daran, das australische Modell nachzuahmen, also ein Social-Media-Verbot für Minderjährige plus Alterskontrollen. Der französische Präsident Emmanual Macron hat sich prominent dafür eingesetzt, ein ähnliches Modell nach Frankreich zu bringen. Verabschiedet hat das Parlament aber nur das Social-Media-Verbot ohne eine ausdrückliche Pflicht für Plattformen zu Alterskontrollen.
Dass der DSA dabei im Weg steht, ist keine Überraschung. So geht es aus dem Gesetzestext selbst hervor, und so erklären es auch Jurist*innen immer wieder, darunter die Wissenschaftlichen Dienste des Bundestags.
Spannend ist die aktuelle Stellungnahme der EU trotzdem, denn sie zeigt, wie sich EU-Kommission und Mitgliedstaaten – in diesem Fall Frankreich – unter Druck setzen.
Vordergründig könnte man den Eindruck gewinnen, beim Kinder- und Jugendschutz im Netz ziehen EU-Kommission und Mitgliedstaaten an einem Strang. Altersbeschränkungen und strenge Kontrollen wollen Kommission und fast alle Mitgliedstaaten gleichermaßen. Im April hatte Macron für dieses Thema zu einer Videokonferenz geladen. Zu Gast waren unter anderem EU-Kommissionspräsidentin Ursula von der Leyen (CDU), Bundeskanzler Friedrich Merz (CDU) und die italienische Ministerpräsidentin Giorgia Meloni (Fratelli d’Italia). Das Ziel: koordiniertes Vorgehen.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Im Juli hat von der Leyen schließlich die Ergebnisse von zwei Gesundheits-Expert*innen vorgestellt, die im Auftrag der EU-Kommission Altersbeschränkungen und Alterskontrollen empfohlen haben. Dabei erwähnte von der Leyen auch die „Erfahrungen aus den Mitgliedstaaten“. Bis Ende des Sommers wolle die Kommission einen eigenen Vorschlag für eine EU-weite Regelung machen. So weit, so harmonisch.
Anders ist der Tonfall jedoch beim Notifizierungsverfahren. Die Stellungnahme der EU-Kommission zeugt von Unstimmigkeiten. Im Zentrum steht die Frage, wie Frankreich das Social-Media-Verbot durchsetzen möchte. Wie, wenn nicht durch verpflichtende Alterskontrollen, soll das klappen? Diese Frage beschäftigt offenbar auch die EU-Kommission. Sie schreibt fast schon verwundert, der Entwurf „scheint“ sich auf das bloße Mindestalter zu beschränken – also ohne, dass Plattformen Alterskontrollen einführen müssten.
Dennoch betont die EU-Kommission sicherheitshalber, der Entwurf aus Frankreich solle nicht so ausgelegt werden, dass er Anbietern von Online-Plattformen über den DSA hinausgehende zusätzliche Verpflichtungen auferlegt. Denn solche Verpflichtungen würde die Kommission mit dem DSA als „unvereinbar ansehen“.
Macron verspricht mehr, als er halten kann
Die rechtlichen Spielräume für den französischen Vorstoß sind also sehr schmal. Entsprechend schmal ist auch der Text, auf den sich das Parlament letztlich geeinigt hat: Er beschreibt vor allem das Social-Media-Mindestalter von 15 Jahren ohne klare Vorgaben zur Durchsetzung. Zuvor hatten Plattformen wie Instagram und TikTok ihr Mindestalter selbst festgelegt, und zwar bei 13 Jahren.
Verkauft hat Emmanuel Macron sein Gesetz etwas anders. „Ich hatte es versprochen – jetzt ist es beschlossen“, prahlte er auf dem Twitter-Nachfolger X. Zum nächsten Schuljahr seien soziale Medien für unter 15-Jährige verboten. Ein reißerischer Videoclip soll die Gefahren sozialer Medien zeigen, etwa Inhalte zu Essstörungen und selbstverletzendem Verhalten. Die Botschaft: Das habe nun ein Ende.
Was sich für junge Menschen in Frankreich aber praktisch ändert, liegt zunächst in der Hand der Plattformen. Sie könnten nun freiwillig einen Beitrag dazu leisten, dass Minderjährige in Frankreich keinen Zugang mehr haben. Zumindest ein Stück weit geschieht das bereits – die Grenzen sind bei näherer Betrachtung fließend. Denn schon jetzt suchen beispielsweise TikTok, Instagram oder YouTube im Hintergrund nach Hinweisen auf Konten von Minderjährigen.
Dabei verarbeitet Software verschiedene Daten, zum Beispiel, wie Menschen die Plattform nutzen. Erhärtet sich ein Verdacht, verlangt die Plattform eine Altersprüfung. Im Gegensatz zu strengen Kontrollen, etwa auf Basis von Dokumenten, sind solche Systeme von Außen jedoch kaum nachvollziehbar. Allein die Plattformen wissen, wie lax oder streng die Kontrollen sind.
Frankreich setzt einen Anker
Der Vorstoß aus Frankreich dürfte eher eine strategische Funktion haben, und zwar mit Blick auf die EU-Kommission, die gerade an einem eigenen Vorschlag arbeitet. Eine EU-weite Regelung könnte zum Beispiel den DSA nachschärfen, sodass es keine Hürden mehr gibt, Plattformen zu Alterskontrollen zu verpflichten.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Formell kann nur die EU-Kommission Gesetze vorschlagen, über die danach EU-Parlament und EU-Mitgliedstaaten verhandeln. Dabei kann sie jedoch auf Initiativen aus den EU-Ländern reagieren – etwa auf nationale Gesetze, die ohne einen EU-weiten Rechtsrahmen auf tönernen Füßen stehen.
So läuft es nun beim Social-Media-Verbot. Frankreich hat die eigene Position bereits in ein Gesetz gegossen, noch bevor die EU-Kommission ihren Aufschlag machen konnte. Damit setzt Frankreich einen Anker für die öffentliche Debatte und für kommende Verhandlungen. Was auch immer die EU-Kommission nun plant, sie muss sich dazu verhalten, zumal Frankreich eines der mächtigsten EU-Länder ist.
Mindestens zwei Passagen der Stellungnahme zeigen, dass auch die EU-Kommission die kommenden Verhandlungen schon im Blick hat. „Die Kommission betrachtet die Festlegung eines Mindestalters, ab dem Anbieter von Online-Diensten für soziale Netzwerke Minderjährigen den Zugang gewähren dürfen, als ein erstrebenswertes Ziel“, heißt es. Und: Nationales Recht könne eine „Übergangslösung“ sein, bis es EU-weite Vorschriften gibt. Das lässt sich als Entgegenkommen deuten.
Derweil macht nicht nur Frankreich Druck. Viele weitere EU-Mitgliedstaaten diskutieren oder planen nationale Social-Media-Verbote, darunter Griechenland und Spanien. Die deutsche Bundesregierung hat noch keine Position. Eine Übersicht hat die in Berlin ansässige Denkfabrik Interface veröffentlicht.
Es gibt Alternativen zu Verboten und Kontrollen
Jüngst hat die Bundesregierung in Österreich ihren Gesetzentwurf vorgelegt. Die Altersgrenze liegt in diesem Fall bei 14 Jahren, auch strenge Alterskontrollen stehen drin. Die EU-Kommission wird nun auch diesen notifizierungspflichtigen Vorstoß prüfen. Es wäre folgerichtig, wenn sie auch Österreichs Pläne für verpflichtende Alterskontrollen zurückweist, weil die Rechtslage in der EU das nicht hergibt – noch nicht.
Während Regierungen und Parlamente EU-weit darum wetteifern, wer zuerst Verbote und Kontrollen verhängt, fällt etwas Wichtiges unter den Tisch. Es sind die dringenden Warnungen und Forderungen von Expert*innen aus unter anderem Kinderschutz, Elternverbänden, Medienpädagogik, IT-Sicherheit und Datenschutz. Sie sehen Altersbeschränkungen und Alterskontrollen kritisch oder lehnen sie ab. Neben Ausschluss und Diskriminierung droht ein Apparat zur Massenüberwachung.
Viele Fachleute pochen auf Alternativen, etwa sicherere, altersgerechte Räume, leicht zugängliche Werkzeuge für elterliche Kontrolle und ein Hilfssystem aus Vertrauenspersonen für Kinder, Jugendliche und Familien. Konkrete Konzepte dafür gibt es: Ein deutsches Expert*innen-Gremium hat insgesamt 56 Empfehlungen vorgelegt, um junge Menschen in der digitalen Welt besser zu schützen. Nur zwei davon handeln von Altersbeschränkungen und ‑kontrollen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Mit der geplanten Geheimdienstreform sollen BND und Verfassungsschutz viele neue Befugnisse bekommen. In einem Krieg würden noch mehr Schranken fallen. Doch die Machtverschiebung zugunsten der Spion:innen kann schon deutlich vorher beginnen.

Im September 2025 verkündete Bundeskanzler Friedrich Merz (CDU): „Wir sind nicht im Krieg, aber wir sind auch nicht mehr im Frieden.“ In der gleichen Woche forderte der CDU-Abgeordnete Roderich Kiesewetter mit Blick auf russische Drohnen in europäischem Luftraum, man müsse den Spannungsfall ausrufen. Das ist die Vorstufe des Verteidigungsfalls, bei der bereits eine Wehrpflicht wieder in Kraft treten würde. Ein in der Geschichte der Bundesrepublik noch nie eingetretener Zustand, der Vorbereitungen zur Landesverteidigung ermöglichen soll.
Die Botschaft beider Äußerungen: Der lange angenommene friedliche Normalzustand existiert nicht mehr, Gesellschaft und Politik müssen sich darauf einstellen.
Eine Mehrheit, die Kiesewetters Schlagzeilen-trächtige Forderung unterstützte, fand sich nicht. Schon gar keine Zweidrittelmehrheit im Bundestag, der einen solchen Spannungsfall feststellen müsste. Doch Wehr- und Kriegstüchtigkeit als wichtiges Ziel ist seitdem nicht nur in Reden und Interviews von Sicherheitspolitiker:innen eingesickert. Sie findet sich auch in neuen Gesetzen. Darunter die geplante Geheimdienstreform, ein fast 700 Seiten schwerer Koloss, die zivilgesellschaftliche Verbände und andere Fachleute etwa als „uferlos“ und „in Teilen verfassungswidrig“ kommentieren.
Einige der neuen Regelungen für den Bundesnachrichtendienst (BND) und das Bundesamt für Verfassungsschutz (BfV) drehen sich darum, was passiert, wenn es zu einen Verteidigungs‑, Spannungs- oder Zustimmungsfall kommt. Denn dann sollen die deutschen Geheimdienste noch mehr dürfen als von der Reform sowieso schon vorgesehen – während die zugehörige Kontrolle gegen Null geht. Besonders dem BND würde in diesem Fall ein immenser Befugnisaufwuchs zuteil. „Der Bundesnachrichtendienst wird unmittelbar in die (aktive) Verteidigung der Bundesrepublik Deutschland eingebunden“, heißt es in der Begründung zu dem Gesetzentwurf. Um „technische, strukturelle oder organisatorische Voraussetzungen“ soll er sich auch schon vorher kümmern.
Im Ernstfall dürfte der Auslandsgeheimdienst dann öffentliche und nicht-öffentliche Stellen zur Mitwirkung verpflichten. Das heißt einerseits, er könnte – so steht es in der Begründung als Beispiel – das Bundesamt für Sicherheit in der Informationstechnik bitten, ihm „bei der Umleitung von Telekommunikationsverkehren zu unterstützen“. Auf der anderen Seite kann der BND Unternehmen verpflichten, ihm zu helfen. Eine solche Hilfe kann viele Formen annehmen. Der Geheimdienst könnte Personal aus der Privatwirtschaft in Anspruch nehmen, wenn er etwa IT-Fachleute oder Sprachmittler:innen braucht. Er könnte auch IT-Systeme von Tech-Unternehmen und die darüber fließenden Daten mitnutzen. Oder gleich in Räumlichkeiten der Privatwirtschaft einziehen.
Auch der Bundesverfassungsschutz bekäme neue Möglichkeiten. Privatunternehmen müssten ihm „Auskünfte und technische Unterstützung“ geben, er dürfte Minderjährige als V‑Personen anwerben und wird mehr und mehr zur Polizei.
Schranken und Kontrolle fallen weg
Schwellen für den Einsatz von Geheimdienstinstrumenten fallen im Verteidigungs‑, Spannungs- oder Zustimmungsfall weitgehend weg. Der BND dürfte dann auch direkt Daten aus der Kommunikation mit Anwält:innen, Journalist:innen oder Seelsorger:innen verarbeiten. Das ist sonst grundsätzlich verboten. Außerdem fallen Schranken für Daten mit Inlandsbezug, während er sonst rein innerdeutsche Kommunikation in der Regel nicht überwachen darf.
Um dem BND zusätzlich Arbeit zu ersparen, würden auch fast alle Protokollierungs- und Dokumentationspflichten sowie große Teile des Kontrollapparats abgeschaltet. Im Verteidigungsfall entfallen sogar jegliche Vorabkontrolle und jegliche Mitteilungspflicht an den Unabhängigen Kontrollrat.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Auch der Bundesverfassungsschutz dürfte im Ernstfall die „Datenpflege in Dateisystemen“ großteils links liegen lassen, „wenn sie mit zusätzlichen Verwaltungsaufwänden verbunden sind.“ Datenschutzkontrollen können eingeschränkt werden und der Unabhängige Kontrollrat könnte dem Inlandsgeheimdienst Pauschalfreigaben für Maßnahmen erteilen, die sich ähneln.
Hendrik Hegemann, der am Institut für Friedensforschung und Sicherheitspolitik an der Universität Hamburg unter anderem zu innerer Sicherheit forscht, sieht in der Kontrolleinschränkung ein Problem. „Die Kontrolle von Nachrichtendiensten ist sowieso schon eine herausfordernde Tätigkeit“, so der Politikwissenschaftler. Das liege zum einen an der personellen Ausstattung der Kontrollgremien, die nicht mit dem Apparat der Geheimdienste mithalten kann. Zum anderen aber auch an der riesigen Menge an Daten, die die Dienste verarbeiten. Wenn dann noch viele Protokollierungs– und Berichtspflichten wegfallen, käme das „on top zu schon bestehenden Herausforderungen“.
Auch der frühere Bundesdatenschutzbeauftragte Ulrich Kelber kritisiert die weitreichenden Ausnahmen im Kontrollregime: „In einer akuten Krise ist sicherlich Flexibilität im Handeln notwendig“, schreibt er. „Doch ohne verlässliche Aufzeichnungen ist nicht nur die laufende Aufsicht erschwert. Auch eine spätere Prüfung durch Gerichte, Parlament und Untersuchungsausschüsse wird unmöglich.“ Das heißt: Was der BND im Ernstfall täte, würden sowohl die Öffentlichkeit als auch Kontrollinstanzen wohl niemals erfahren. Nicht einmal eine nachträgliche Diskussion wäre dann möglich.
Doch was sind eigentlich die Voraussetzungen dafür, dass die rechtsstaatlichen Hürden für den Geheimdienst derart abgebaut werden?
Was sind Verteidigungs‑, Spannungs- und Zustimmungsfall?
Der Verteidigungsfall tritt dann ein, wenn Deutschland „mit Waffengewalt angegriffen wird oder ein solcher Angriff unmittelbar droht“. Im Regelfall braucht es eine Zweidrittelmehrheit des Bundestages, um den Verteidigungsfall auszurufen. Er beschert dem Bundeskanzler etwa die Befehls- und Kommandogewalt über das Militär, Bundestag und Bundesrat schrumpfen im Krieg auf ein Notparlament mit dem Namen „Gemeinsamer Ausschuss“ zusammen, wenn der Bundestag nicht mehr arbeitsfähig ist. Das alles und mehr regelt das Grundgesetz.
Weniger genau beschreibt die Verfassung den Spannungsfall, die Vorstufe des Verteidigungsfalls. „Was das genau ist und was daraus folgt, ist gar nicht so klar“, sagt Politikwissenschaftler Hegemann. „Die Logik dahinter ist: Man muss nicht warten, bis feindliche Armeen mit ihren Panzern die Grenze überschreiten. Sondern man darf bestimmte Schritte davor schon einleiten: Etwa dafür sorgen, dass Lebensmittel und Energie vorgehalten werden oder Krankenhäuser sich vorbereiten.“
Welche Voraussetzungen dafür genau gelten, definiert das Grundgesetz nicht. Doch auch hier müssen zwei Drittel der Abgeordneten zustimmen.
Anders sieht das beim Zustimmungsfall aus, vereinfacht gesagt ist das so etwas wie ein teilweiser Spannungsfall. „Der Zustimmungsfall wird dann relevant, wenn der Bundestag einzelne Regelungen in Kraft setzen will, die im Spannungsfall gelten würden, aber den Spannungsfall insgesamt noch nicht ausrufen will“, sagt Hegemann. Für diese einzelnen Regeln reicht dann wie bei regulären Gesetzen grundsätzlich eine einfache Mehrheit im Parlament.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
„Orientierung“ am Grundgesetz
Das geplante BND-Gesetz formuliert für alle drei Fälle Regeln. Vor allem aber ändert es den Mechanismus, wie der Zustimmungsfall für das BND-Gesetz ausgelöst werden kann. Das soll sich am Zustimmungsfall aus dem Grundgesetz „orientieren“, aber umgeht dabei das Plenum des Bundestags.
An die Stelle eines regulären parlamentarischen Verfahrens soll nämlich ein Vorschlag der Bundesregierung treten, dem das Parlamentarische Kontrollgremium zustimmen müsste. Dann könnten einzelne oder alle Regelungen des Gesetzes zum Spannungs- und Verteidigungsfall „freigeschaltet“ werden. Dass der Bundestag als Ganzes dabei außen vor bliebe, hat noch einen weiteren Effekt: „Eine Veröffentlichung ist nicht vorgesehen. Eine öffentliche politische Diskussion findet damit auch nicht statt“, schreibt der frühere Ministerialdirektor Peter Schantz in einer Stellungnahme auf Bitte der Gesellschaft für Freiheitsrechte (GFF).
Das heißt: Es könnten Kontrollen wegfallen und Kompetenzen in Kraft treten, ohne dass es jemand mitbekäme. Schantz bewertet die Konstruktion als verfassungswidrig. „Derart weite und unbestimmte Befugnisse und Grundrechtseinschränkungen sind daher nicht mit dem Grundgesetz vereinbar“, so Schantz.
Auch Ulrich Kelber bezeichnet den eigens für den BND formulierten Zustimmungsfall als „verfassungsrechtlich fragwürdige Machtverschiebung weg vom gewählten Parlament“.
Doch was wäre eine gute Lösung für den Ernstfall? Hegemann sieht das grundsätzliche Problem, dass Notstandsgesetze nicht gut zu hybriden Angriffen wie etwa Attacken auf IT-Systeme, Sabotage oder Desinformationskampagnen passen. „Hybride Angriffe haben keinen klaren Anfang und kein klares Ende“, so Hegemann. „Das ist anders, als es bei den Notstandsregeln gedacht war. Da ging man davon aus: Ein Notstand tritt ein und irgendwann endet er.“ Er glaubt daher nicht, dass es die Antwort sein kann, Notstandsregelungen, die für den Fall klassischer bewaffneter Konflikte gedacht waren, im Fall derartiger Bedrohungen zu nutzen. Aber – so der Forscher – man befinde sich da in einem Dilemma. „Wir müssen uns unterhalb dieser Schwelle Möglichkeiten überlegen, die gleichzeitig nicht der Normalzustand sind.“ Dann aber mit geregelter Kontrolle und Dokumentation.
Die geplanten Änderungen für die Geheimdienste befinden sich derzeit im Stadium eines Referentenentwurfs. Das bedeutet, sie sind innerhalb der Regierung noch nicht final abgestimmt. Ein Kabinettsbeschluss ist derzeit für Mitte August geplant. Dann kann die Bundesregierung ihren Entwurf dem Bundestag übergeben, der nach der parlamentarischen Sommerpause seine Arbeit am Entwurf beginnen kann.
Anmerkung d. Redaktion, 29. Juli: Halbsatz zur Rolle des Gemeinsamen Ausschusses zwecks Korrektur ergänzt.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Nach dem Anschlag auf den Christopher Street Day in Berlin ist der Schock groß. Doch die Reaktionen der führenden CDU-Politiker lassen sich leicht als bloße Heuchelei entlarven. Ein Kommentar.

Das Entsetzen, der Schock und die Trauer sind groß über den Anschlag auf den Berliner Christopher Street Day am Samstag. Ein mutmaßlicher Täter ist mit einem Kleintransporter in eine Menschenmenge am Rande des CSDs im Tiergarten gefahren und hat mindestens eine Person getötet sowie 29 weitere Menschen zum Teil schwer verletzt.
Bestürzungen und Beileidsbekundungen führender Politiker ließen nicht lang auf sich warten. Vielen Queers sind sie aber übel aufgestoßen. Denn an schamloser Heuchelei sind diese nicht zu überbieten.
Kanzler Friedrich Merz (CDU) beispielsweise hat an den Zusammenhalt appelliert und rief dazu auf, sich durch solche Taten nicht spalten zu lassen. Dabei beherrscht Merz die Kunst, die Gesellschaft zu spalten und Hetze zu verbreiten, selbst vorbildlich: Erinnert sei hier lediglich an seine Zirkuszelt-Aussage aus dem letzten Jahr. Damals verteidigte er die Entscheidung seiner Kollegin Julia Klöckner (CDU), anlässlich des CSD keine Regenbogenfahne auf dem Bundestag zu hissen, mit den Worten, der Bundestag sei „ja nun kein Zirkuszelt“, auf dem beliebig die Fahnen gehisst werden könnten.
Es fühlt sich wie Hohn an
Seit Jahren ist ein Anstieg von queerfeindlichen Anfeindungen, Gewalt und Hass gegen queere Menschen und Einrichtungen zu verzeichnen. Wie hat die Politik darauf reagiert? Mit Kürzungen. Viele zentrale Projekte der Aufklärungs- und Unterstützungslandschaft brechen weg, weil ihnen die Förderung gestrichen wird. Unter Stefan Evers, heute CDU-Bürgermeisterkandidat in Berlin, wurde beispielsweise queersensible Sexualaufklärung an Schulen eingestampft. Das bekommen viele queere Menschen zu spüren und gerade deshalb fühlt sich die nun bekundete Bestürzung wie Hohn an.
Edwin Florina Greve, Referent für Antidiskriminierung beim Migrationsrat Berlin, fasst es so zusammen: „Kanzler Merz, der Regierende Bürgermeister Wegner oder Finanzsenator Evers können mit ihren Worten nicht darüber hinwegtäuschen, dass unter ihrer Verantwortung queere Schutzräume, Unterstützungsangebote und Bildungsprogramme gekürzt oder gestrichen werden und insgesamt nach wie vor unterfinanziert sind.“
Erst kürzlich kam ein neuer Kahlschlag: Das CDU-geführte Familienministerium hat dem bundesweit einzigartigen Jugendnetzwerk Lambda die Finanzierung gestrichen. Damit haben queere Jugendliche, die Hilfe suchen oder mit queerfeindlicher Gewalt konfrontiert sind, in Zukunft möglicherweise keine Anlaufstelle mehr. Dabei steigt weiterhin die Zahl junger Menschen, die sich in akuten Krisen an den Verein wenden.
Dobrindts Angriff auf Rechte von trans Menschen und Zusammenarbeit mit der Taliban
Auch Bundesinnenminister Alexander Dobrindt (CSU) zeigte sich anlässlich der „feigen, abscheulichen Attacke auf friedlich feiernde Menschen“ zutiefst erschüttert. Es ist aber eben derselbe Innenminister, der mit demokratisch äußerst fragwürdigen Manövern eine Verordnung zum Selbstbestimmungsgesetz durchzuboxen versucht, die trans Menschen ein Leben lang einem Zwangsouting bei Behörden unterzieht und ihre äußerst sensiblen Daten wie frühere Vornamen und Geschlechtseinträge automatisch an Sicherheitsbehörden übermitteln will.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Damit setzt er sich nicht nur kaltblütig über Bedenken der Betroffenen hinweg, die darin die Entstehung einer sogenannten Rosa Liste sehen. Er befeuert damit auch das rechtspopulistische Narrativ, dass trans Menschen generell zu misstrauen sei, und rückt sie in die Nähe von Extremismus- und Terrorverdacht.
Die Ermittlungen zum Anschlag sind noch nicht abgeschlossen. Der mutmaßliche Hauptverdächtige, den die Polizei am Sonntag erschossen hat, ist laut Polizeiangaben dem islamistischen Milieu zuzuordnen. Laut Ermittlungen hat er das Auto angemietet. Ob er bei dem Anschlag auch am Steuer des Fahrzeugs saß, ist bisher ungeklärt. Dobrindt sprach von einem mutmaßlich islamistischen Terroranschlag.
Es ist auch derselbe Innenminister, der schamlos mit der extremistischen islamistischen Terrorgruppe Taliban kooperiert, die lesbische, schwule, bisexuelle, trans- und intergeschlechtliche sowie andere queere Menschen in Afghanistan verfolgt, vergewaltigt und ermordet und ihre systematische Vernichtung anstrebt. Dobrindt hat den Kontakt zu den Taliban seit 2025 intensiviert und direkte Gespräch geführt, mit dem Ziel, immer mehr Afghan*innen abzuschieben.
Ergebnis: Sowohl das Generalkonsulat in Bonn als auch die afghanische Botschaft in Berlin werden nun von einem Vertreter der Taliban geleitet. Vier weitere Taliban-Vertreter will Dobrindt nun willkommen heißen – und das obwohl Deutschland die Taliban-Regierung in Afghanistan offiziell gar nicht anerkennt. Abgeschoben werden sollen in einigen Bundesländern neuerdings nicht mehr nur straffällig gewordene Afghan*innen, sondern auch alleinstehende Männer, die sich nichts haben zuschulden kommen lassen.
Geheimdienstreform im Namen der queeren Community?
Es sollte nach der Gewalttat nicht lange dauern, bis Politiker den Anschlag auch für ihre politischen Ziele instrumentalisieren. Mehrere Unionspolitiker forderten erweiterte Befugnisse für Polizei und Geheimdienste. Der innenpolitische Sprecher der Unionsfraktion, Alexander Throm (CDU), sowie auch der stellvertretende Fraktionschef Günter Krings (CDU) drängten auf eine schnelle Verabschiedung der kürzlich ins Rollen gebrachten großen Geheimdienstreform direkt nach der parlamentarischen Sommerpause.
Auch Konstantin von Notz von den oppositionellen Grünen sagte in einem Interview, man müsse die Sicherheitsbehörden mit Befugnissen austatten. Darum gehe es auch in der aktuellen Geheimdienstreform.
Mit dieser Reform sollen der Bundesnachrichtendienst und der Verfassungsschutz mit Befugnissen in beispiellosem Ausmaß ausgestattet und laut Dobrindt zu „echten“ Geheimdiensten werden. Denn sie sollen nicht nur Informationen sammeln und beobachten, sondern auch – wie bisher die Polizei – etwa in IT-Systeme eindringen und bei Cyberangriffen zurückhacken dürfen. Dabei soll ihnen außerdem nicht so genau auf die Finger geschaut werden.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Während BND und Verfassungsschutz mächtiger denn je werden, soll noch stärker in Grundrechte der Bevölkerung eingegriffen werden. Wenn Menschen Sticker kleben oder Plakate abreißen, dürfte das nach den Plänen wohl ausreichen, damit der Verfassungsschutz sie beobachten darf. Wie das der queeren Community helfen soll, bleibt fraglich.
Zudem ist überhaupt nicht klar, ob fehlende Befugnisse der Polizei und der Geheimdienste bei diesem Anschlag ein Problem waren. Der mutmaßliche Attentäter stand unter polizeilicher Beobachtung: Diese hat ihn zeitweise observiert und auch sein Telefon überwacht, wie rbb24 berichtet. Auch seine Wohnung haben die Beamten bereits im Vorfeld des Anschlags durchsucht, nachdem dieser ein Foto von einer Waffe in sozialen Medien gepostet habe. Diese stellte sich als Spielzeugwaffe heraus. Zu behaupten, mit erweiterten Befugnissen hätte der Anschlag verhindert werden können, und diese als das Allheilmittel darzustellen, scheint hingegen ein Leichtes zu sein.
Nicht auf Kosten der queeren Community
Die vernichtende Kritik von zivilgesellschaftlichen Verbänden an diesem umstrittenen Umbau der Geheimdienste nun abschmettern und die Gesetzesnovelle auf Kosten der queeren Community durch den parlamentarischen Prozess durchpeitschen zu wollen, ist mindestens unsensibel. Das Innenministerium hat den Referentenentwurf erst vor einigen Wochen vorgestellt, er wurde im Kabinett noch nicht beraten.
Auch die automatisierte Datenanalyse, mit der die Geheimdienste sensible Daten massenhaft auswerten und Personenprofile erstellen können, und das Vorhaben, den öffentlichen Raum in Echtzeit lückenlos überwachen und biometrische Daten mit Bildern aus dem Internet abgleichen zu dürfen, dürfte kaum im Interesse von queeren Menschen sein. Das würde jedwede Anonymität zerstören, die zuweilen überlebenswichtig ist, wenn man nicht den geschlechtlichen oder sexuellen Normen der Gesellschaft entspricht.
Wir brauchen keine weiteren Grundrechtseingriffe. Was es jetzt braucht, ist die Förderung von Beratungs‑, Unterstützungs- und Aufklärungsprogrammen, Treff- und Kultureinrichtungen – und vor allen Dingen Selbstbestimmung.
Update, 28.7.2026, 14.28 Uhr: Wir haben die Aussage von Konstantin von Notz präzisiert.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Wenn Politiker:innen nicht mehr selbst reden, sondern Maschinen für sich sprechen lassen, mangelt es ihrem Auftritt an Authentizität. Doch gerade die macht einen Teil ihrer Legitimität aus. Denn in einer Demokratie sollten wir von Menschen repräsentiert werden, nicht von Robotern.

In einem Handbuch des IT-Unternehmens IBM aus dem Jahr 1979 steht ein bemerkenswerter Satz: „Ein Computer kann niemals zur Verantwortung gezogen werden. Daher darf ein Computer niemals Führungsentscheidungen treffen.“ Die Regel hat auch knapp 50 Jahre später nicht an Brisanz verloren. Denn die Vermutung liegt nahe, dass zahlreiche Unternehmen inzwischen auch kritische Entscheidungen an KI-Systeme auslagern. Aber was, wenn auch Politiker:innen ihre Funktion gar nicht mehr selbst ausüben, sondern eine Maschine mit der Ausführung beauftragen?
In den vergangenen Wochen haben Vermutungen Aufsehen erregt, dass mehrere Spitzenpolitiker allzu gerne KI ihren Job erledigen lassen. Mario Voigt, Dietmar Woidke und Karsten Wildberger gerieten in den Verdacht, ihre Reden und Gastbeiträge in Medien von KI-Programmen generieren zu lassen. Die Debatte darum, ob und inwieweit dies im Widerspruch zu ihrem Amt steht, wurde zurecht in Teilen heftig und emotional geführt.
Roboter sind keine Repräsentanten
Wir wählen, wer für uns spricht und wer für uns entscheidet. Die Menschen in der Bundesrepublik haben sich vor etwa 80 Jahren für eine repräsentative Herrschaftsform entschieden, bei der gewählte Volksvertreter:innen für die Bevölkerung sprechen und entscheiden. Anders als in direkten Demokratieformen, in der die Menschen immer wieder selbst Entscheidungen treffen. Zentrales Instrument dieser Demokratie sind die Repräsentant:innen selbst. Das heißt, einzelne Menschen, die uns durch ihre eigene Person vertreten.
Eben darin besteht auch ein wesentlicher Teil der Legitimität, die eine repräsentative Demokratie auszeichnet. Wir wählen Menschen zu unseren Vertreter:innen, die durch ihren Verstand, ihr Wesen, ihren Charakter und ihre Fähigkeiten geeignet erscheinen, uns besser zu vertreten als andere das könnten. Und die Legitimität der Repräsentant:innen besteht maßgeblich in ihrer Authentizität.
Legitimität durch Authentizität
In Reden, Äußerungen und Texten zeigt sich, was für ein Mensch die Person ist, die uns vertritt. Welche Meinungen sie hat, welche Werte sie ihren Entscheidungen zugrundelegt und worin ihr Wesen besteht. Dabei sind Reden, Auftritte und Äußerungen ein genauso großer Bestandteil von Politik wie Abstimmungen im Bundestag. Wird all das an eine Maschine ausgelagert, verlieren Repräsentant:innen ihre Authentizität – und damit auch ein Stück ihrer Legitimität.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Menschen wollen von Menschen regiert werden. Darauf beruht das bürgerliche Herrschaftsideal, das sich nach den Revolutionen des 18. Jahrhunderts zu etablieren begann. Menschen sind demnach durch ihren eigenen Verstand dazu befähigt, andere zu vertreten, wenn ihre Mitbürger:innen sie dazu bestimmen. Diese Herrschaftsform kann man gut oder schlecht finden – solange aber keine andere in Deutschland Gültigkeit hat, ist es sie es, die politischem Handeln seine Berechtigung verleiht. Deswegen sollte nicht einmal der Eindruck entstehen, dass hinter dem Handeln eines gewählten Vertreters eine Maschine stehen könnte.
Lieber anecken als glattbügeln
Menschen zeichnet aus, dass sie differenzierte Charaktere sind. Sie haben komplexe Meinungen und Wertesysteme, ihre Worte klingen bestenfalls nicht nach hohlen Business-Phrasen und manchmal überraschen sie durch eine bestimmte Einstellung, die wir so nicht von ihnen erwartet hätten. Und: Sie haben immer auch ein eigenes Verhältnis sowohl zu dem Thema, über das sie sprechen als auch zu den Personen, mit denen sie kommunizieren. All das kann ein KI-System nicht.
Statt echten Gefühlen, kontroversen Äußerungen und komplexen Einstellungen klingen Ausgaben von KI-Systemen meist künstlich erzeugt, weichgewaschen, ausgelutscht.
Noch wichtiger aber als der Stil ist der Inhalt: ChatGPT und Claude bilden auch Positionen gerne sanfter, Meinungen weniger kontrovers und Ideen weniger radikal ab, als sie sind. Wenn Politiker:innen KI nutzen, um etwa Reden zu schreiben, dann laufen sie Gefahr, dass ihre eigene Positionen an Klarheit verlieren und sich damit weniger von denen anderer politischer Akteure unterscheidet.
Und es drängt sich die Frage auf: Wenn ein Repräsentant schon seine eigenen Äußerungen nicht mehr selbst formuliert – wieso sollten wir dann glauben, dass er nicht bald auch seine Entscheidungsfindung an Open AI oder Anthropic auslagert?
KI macht uns nur überflüssig, wenn wir sie lassen
Ähnlich verhält es sich mit dem Gebrauch von KI zur Textgenerierung durch Medienhäuser.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Menschen, die Medien konsumieren, vertrauen zuallererst den Menschen, die die medialen Inhalte produzieren – den Journalist:innen. Die Standards und Fähigkeiten der Personen, die ein Medium gestalten, machen ein Medium erst vertrauenswürdig. Deswegen ist es weder innovationsfeindlich noch selbstbeweihräuchernd, wenn sich Redaktionen dazu entscheiden, keine KI für ihre Texte zu nutzen. Eine solche Entscheidung beruht vielmehr auf dem Wissen darum, was ihre Daseinsberechtigung ausmacht: die Authentizität und Integrität derer, die das Medium schaffen.
Wir vertrauen weniger einer Institution oder einem Amt als vielmehr den Menschen, die dessen Funktionen ausfüllen. Das gilt für Journalist:innen wie für Politiker:innen. Wenn sie aber ihre Arbeit von einer KI ausführen lassen, kann ich den Computer auch gleich selbst bedienen.
Das löst das Problem nicht – und damit zurück zu dem Eingangssatz aus dem IBM-Handbuch. Denn eine Maschine kann niemals zur Verantwortung gezogen werden.
Dass wir Menschen für ihr Handeln verantwortlich machen, wählen oder abwählen können, ist aber ein weiterer zentraler Grund dafür, warum Menschen demokratischen Systemen vertrauen. Wenn Politiker:innen also glauben, sie könnten ihre Arbeit kurzerhand von einer KI erledigen lassen – und sei es auch „nur“ zum Erstellen einer Rede oder eines Artikels –, dann stellen sie damit nicht nur die Legitimität ihrer eigenen Funktion infrage, sondern auch das Funktionieren des politische Systems selbst.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die 30. Kalenderwoche geht zu Ende. Wir haben 12 neue Texte mit insgesamt 95.849 Zeichen veröffentlicht. Willkommen zum netzpolitischen Wochenrückblick.

Liebe Leser:innen,
freut ihr euch auch so, dass Friedrich Merz endlich wieder in der Vorhand ist? Erst kann er bei wichtigen Reformvorhaben punkten und jetzt kommt der große Befreiungsschlag durch Wechsel auf Top-Positionen seines Teams. Wobei: Vielleicht hat Merz den Neustart doch verstolpert, weil sein Wunschkandidat für den Posten des Verkehrsministers abgesagt hat?
Auch wenn um die Halbzeit-Sommerpausen-Bilanz noch gerungen wird, eines steht fest: Definitiv zur Hochform aufgelaufen ist mal wieder Politikjournalismus im Stil von Sportberichterstattung. Versteht mich nicht falsch: Natürlich sind Personalien und Aushandlungsprozesse wichtig – aber gab es nicht noch Inhalte, über die Menschen diskutieren und Medien berichten sollten?
Unausgewogen und gefährlich
Bei uns standen diese Woche zwei schwarz-rote Reformvorhaben im Fokus, die es in sich haben: die Aufrüstung der Geheimdienste und der Angriff auf die staatliche Transparenz.
Zur Geheimdienstreform haben wir zahlreiche Stellungnahmen durchwühlt, die in einer demokratieverachtend kurzen Frist eingereicht werden mussten und trotzdem eine deutliche Sprache sprechen: Verfassungswidrig! Verfassungswidrig! Verfassungswidrig! Denn Innenminister Dobrindt will die Befugnisse von BND und Verfassungsschutz massiv ausbauen sowie gleichzeitig die Transparenz und externe Kontrolle ihrer Arbeit schwächen.
Diese „unausgewogene und gefährliche Mischung“ könne sich eine freiheitliche Demokratie nicht leisten, lautet auch das klare Fazit, das der ehemalige Bundesdatenschutzbeauftragte Ulrich Kelber in einem Gastbeitrag zieht.
Das Innenministerium agiert hier wieder mal nach dem Motto: Wer nichts zu verbergen hat, hat auch nichts zu befürchten. Und man fragt sich unwillkürlich: Wenn zur gleichen Zeit das Informationsfreiheitsgesetz so weit geschleift werden soll, dass Behörden keine Transparenz mehr zu befürchten haben – heißt das, der Staat hat etwas zu verbergen?
Journalist:innen sollen ausgeschlossen werden
Das Informationsfreiheitsgesetz ist eine der zentralen demokratischen Errungenschaften der vergangenen 20 Jahre. Ihm haben wir es zu verdanken, dass das noch vom Geist des preußischen Obrigkeitsstaates beseelte Amtsgeheimnis aufgehoben wurde und Behörden auf Anfrage Informationen herausgeben müssen – von Protokollen und Vermerken über Verträge bis zu Studien und Daten.
Schon seit Anfang Juli wissen wir, dass die Spitzen von Union und SPD dieses Recht beschneiden wollen. Konkret sollen unter anderem neue Ausnahmen hinzukommen, Gebührendeckel gestrichen und der Kreis der Antragsberechtigten drastisch verkleinert werden. Nach einhelliger Meinung würde das dazu führen, dass die Informationsfreiheit im Bunde de facto abgeschafft werden würde.
Insbesondere Journalist:innen wären betroffen, weil sie im Rahmen ihrer Arbeit gar keine IFG‑, sondern nur noch Presseanfragen stellen könnten. Diese Woche konnte nun der MDR unter Berufung auf interne Vermerke aus dem Innenministerium berichten: Das ist kein Zufall, spätestens seit Februar 2026 arbeitet das Haus von Minister Dobrindt gezielt darauf hin, Journalist:innen und Transparenzplattformen wie FragDenStaat auszuschließen.
Doppelt dreist
Letzteres ist doppelt dreist, weil die Kolleg:innen von FragDenStaat nicht nur hervorragende Recherchearbeit machen, sondern mit ihrer Plattform dem IFG überhaupt erst zu seinem Recht verhelfen. So einfach wie dort kann man deutschen Behörden sonst nirgends Anfragen stellen, mehr als 130.000 Menschen haben die Möglichkeit bisher genutzt.
Auch für unsere Arbeit bei netzpolitik.org haben Informationsfreiheitsgesetze und FragDenStaat eine herausragende Bedeutung. Auf Presseanfragen erhält man viel zu oft keine Antwort, auf IFG-Anfragen fast immer. Und falls nicht, kann man die Bundesbeauftragte für Informationsfreiheit mit Bitte um Vermittlung anrufen.
Erst vor wenigen Wochen konnten wir aufdecken, dass deutsche Landeskriminalämter bei der Informationsbeschaffung auch auf Databroker zurückgreifen. Die haben Daten aus der Online-Werbung im Angebot, die in der Regel illegal gesammelt wurden. Dabei half uns auch das IFG, die Anfragen haben wir natürlich über FragDenStaat gestellt.
Wer FragDenStaat angreift, greift uns alle an
Um das klar zu sagen: Wer FragDenStaat angreift, der greift uns alle an. Und wer Transparenz schwächt, während er bei der Überwachung aufrüstet, der betreibt einen autoritären Umbau des Staates.
Also konzentrieren wir uns auf das Wesentliche: Das Thema sollte nicht sein, wie schnell die Merz-Regierung Reformen durchbekommt. Oder wer in der Koalition dabei die meisten Punkte macht. Sondern wir sollten darauf schauen, was Schwarz-Rot mit diesem Land vorhat und welche Folgen das für unsere Demokratie haben wird.
Wir bleiben für euch am Ball.
Euer Ingo
Trugbild: Eine Frage der Qualität
Der Einsatz sogenannter künstlicher Intelligenz im Kreativbereich ist schambehaftet und wird in der Regel argwöhnisch beäugt. Dabei zählt am Ende die Qualität eines Werkes – und die müssen wir erst einmal erkennen. Von Vincent Först –
Artikel lesen
Offener Brief gegen ZDF-Entscheidung: „Wir halten die Absage für einen Fehler“
Die Entscheidung des ZDF, einen Auftritt des Rappers Danger Dan und des Pianisten Igor Levit aus dem Programm zu nehmen, schlägt hohe Wellen. In einem offenen Brief kritisieren mehrere Fernsehräte, dass der Sender damit die Chance vergeben habe, eine Debatte über den Umgang mit Rechtsextremismus anzustoßen. Von Erik Tuchtfeld –
Artikel lesen
Justizstatistik 2024: Polizei hackt alle fünf Tage mit Staatstrojanern
Die Polizei nutzt immer öfter Staatstrojaner. Im Jahr 2024 durfte sie 129 Mal Geräte hacken und ausspionieren, 79 Mal war sie damit erfolgreich. Das ist neuer Rekord. Anlass sind wie immer vor allem Drogendelikte. Von Andre Meister –
Artikel lesen
Chatbots und Schwangerschaftsabbrüche: Gut gemeint, schlecht informiert
Chatbots wirken auch bei persönlichen Fragen oft wie eine neutrale Instanz. Unsere Recherche zeigt, wie sehr das bei einem Schwangerschaftsabbruch täuschen kann – besonders dann, wenn man ChatGPT um Rat fragt. Von Mayya Chernobylskaya –
Artikel lesen
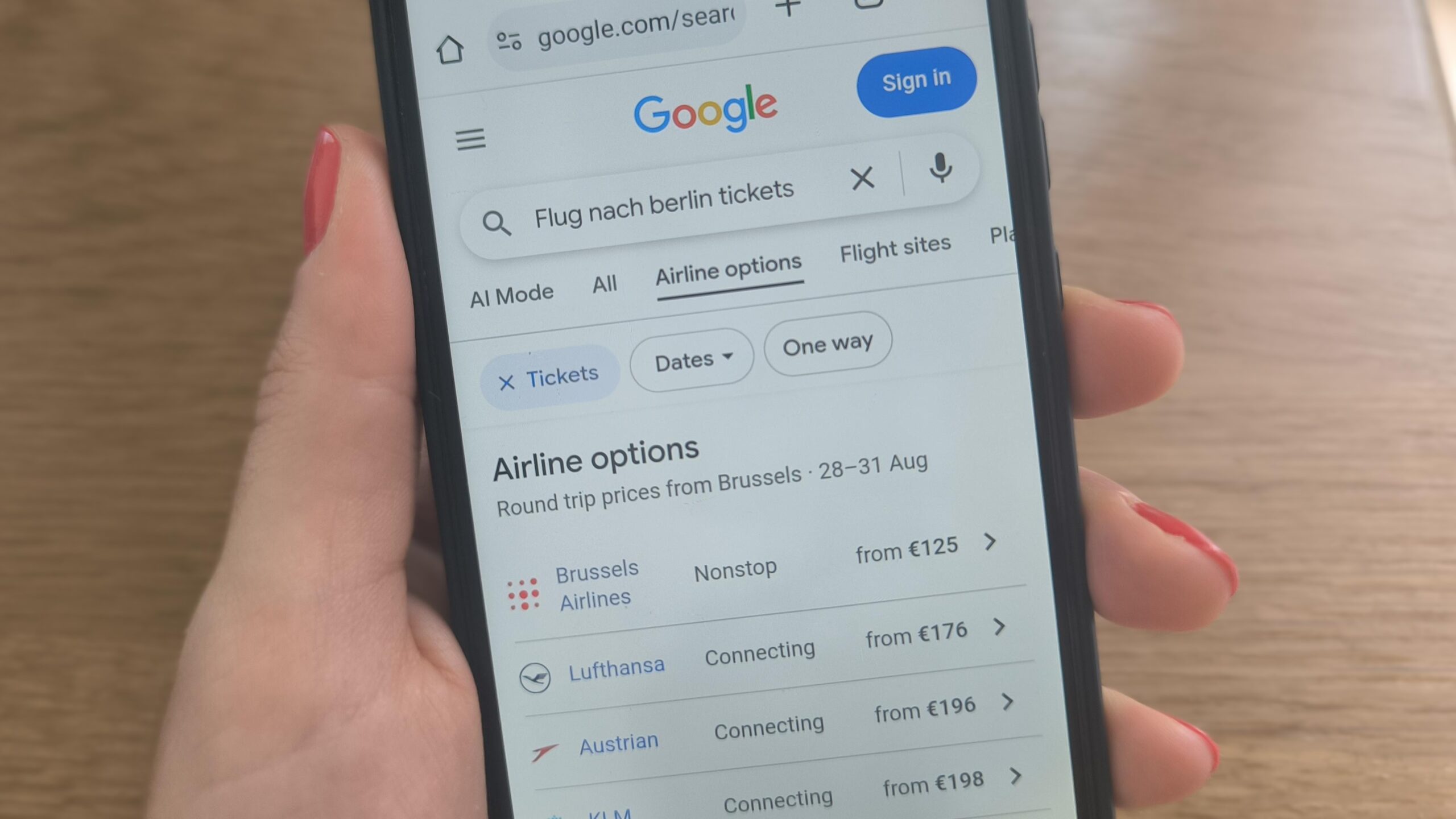
Social-Media-Verbot bis 15 Jahre: Frankreich wählt den falschen Weg
Das französische Parlament hat sich auf ein Social-Media-Verbot für unter 15-Jährige geeinigt. Das wird die digitale Welt für junge Menschen nicht sicherer machen und gefährdet alle. Denn es bereitet den Weg für ein Internet, das nur noch mit Ausweiskontrolle zugänglich ist. Ein Kommentar. Von Sebastian Meineck –
Artikel lesen
Geheimdienst-Gesetz: Maßlos, unkontrolliert und intransparent
Die Bundesregierung will den Geheimdiensten neue Befugnisse im bisher beispiellosen Ausmaß geben. Zugleich schwächt sie Betroffenenrechte, unabhängige Aufsicht und Möglichkeiten für Transparenz. Eine freiheitliche Demokratie kann sich diese unausgewogene und gefährliche Mischung nicht leisten. Von Gastbeitrag, Ulrich Kelber –
Artikel lesen
FragDenStaat & Co.: Dobrindt will Transparenz-Plattformen aus dem Weg räumen
Jüngst hatte der Koalitionsausschuss der Bundesregierung beschlossen, das Informationsfreiheitsgesetz drastisch einzuschränken. Nun zeigt ein Bericht des MDR, dass Innenminister Dobrindt noch viel weiter gehen will, um staatliches Handeln im Geheimen zu belassen. Von Tomas Rudl –
Artikel lesen
Unfairer Wettbewerb: EU-Kommission verhängt 890-Millionen-Euro-Strafe gegen Google
Die Suchergebnisse von Google sollen in Europa bald anders aussehen. Im Rahmen des Digital Markets Act (DMA) hat die EU-Kommission erstmals zwei Strafen gegen Google verhängt. Obwohl es um verhältnismäßig wenig Geld geht, dürfte die Entscheidung in den USA trotzdem für Unmut sorgen. Von Anna Ströbele Romero –
Artikel lesen
Stellungnahmen zur Geheimdienstreform: „Ein erheblicher Überwachungsdruck für die Gesellschaft“
Das Urteil verschiedener zivilgesellschaftlicher Verbände und der Bundesdatenschutzbeauftragten fällt eindeutig aus: Die geplante Geheimdienstreform von Bundesinnenminister Dobrindt ist unverhältnismäßig und verletzt vielfach die Grundrechte. Verfassungsschutz und BND werden hingegen mächtiger denn je. Von Daniel Leisegang –
Artikel lesen
Polizeigesetz-Erweiterung in Schleswig-Holstein: Schwarz-Grün will dich beim Autofahren filmen
Die Regierungskoalition von Schleswig-Holstein hat die sowieso schon überbordende Polizeigesetznovelle noch einmal deutlich verschärft. Künftig sollen KI-Kameras Handysünder jagen, bewaffnete Drohnen erlaubt und heimliches Filmen und Abhören einfacher werden. Von Martin Schwarzbeck –
Artikel lesen
EU-Kommission: TikTok soll Teenager-Konten strenger abschirmen
TikTok macht es Fremden zu leicht, die Accounts von Minderjährigen zu finden. Nach Auffassung der EU-Kommission verstößt die Plattform damit gegen den Digital Services Act. Zu Alterskontrollen bei TikTok äußert sich Brüssel noch nicht. Von Anna Ströbele Romero –
Artikel lesen
Digitaler Kolonialismus: Wie die US-Regierung afrikanischen Ländern Daten-Deals aufzwingt
Nach der Einstellung von USAID arbeiten die USA an Nachfolgeprogrammen zur Unterstützung der Gesundheitsversorgung in afrikanischen Ländern. Doch Hilfe beim Kampf gegen Ebola, HIV und Co. gibt es künftig nur noch gegen weitreichenden Zugang zu Gesundheitsdaten. Von Ingo Dachwitz –
Artikel lesen
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Nach der Einstellung von USAID arbeiten die USA an Nachfolgeprogrammen zur Unterstützung der Gesundheitsversorgung in afrikanischen Ländern. Doch Hilfe beim Kampf gegen Ebola, HIV und Co. gibt es künftig nur noch gegen weitreichenden Zugang zu Gesundheitsdaten.

Als Donald Trump Anfang 2025 seine zweite Amtszeit antrat, dauert es nicht lange, bis seine Regierung damit begann, ihr Programm globaler Hilfezahlungen (USAID) abzuwickeln. Unter Regie von Elon Musks DOGE wurden die USAID-Zuwendungen binnen weniger Wochen erst eingefroren und dann fast vollständig eingestellt. Die Gelder unterstützten unter anderem die Gesundheitsversorgung und den Infektionsschutz in zahlreichen afrikanischen Ländern. Prognosen gehen davon aus, dass ihre Streichung das Leben von Millionen Menschen kosten wird.
Eine Recherche des US-Mediums ProPublica aus dem Juni zeigt: Im Rahmen der America First Global Health Strategy nehmen die USA manche Unterstützung in geringerem Umfang wieder auf – aber offenbar nur, wenn Empfängerländer dem Ausverkauf von Gesundheitsdaten zustimmen. Die Verträge sehen demzufolge unter anderem weitreichende Zugangsrechte zu Gesundheitsdatensystemen, Patientenakten und Labordaten vor.
50 solcher Vereinbarungen will die US-Regierung mit unterschiedlichen Ländern abschließen, nach Informationen von ProPublica ist das bisher erst mit neun Ländern gelungen. Trotz Kritik aus der Zivilgesellschaft unterzeichneten etwa Nigeria, Kenia, Uganda und die Demokratische Republik Kongo die Vereinbarungen. Andere Länder wie Sambia, Simbabwe und Ghana haben die Forderungen der US-Seite zurückgewiesen.
„Wenn man das Angebot annimmt, wird man ausgebeutet. Wenn man es ablehnt, stirbt man“, so beschreibt der ugandische Rechtsanwalt und Digital-Rights-Experte Frank Ssekamwa die Lage gegenüber ProPublica. „Das ist der Inbegriff des digitalen Kolonialismus.“
Gesundheitsdaten gegen Gesundheitsversorgung
Obwohl die Vereinbarungen geheimgehalten werden, konnte ProPublica mehrere davon einsehen. Kenia etwa soll in fünf Jahren 1,6 Milliarden US-Dollar erhalten und garantiert den USA im Gegenzug sieben Jahre umfangreichen Zugang zu Gesundheitsdaten.
Ähnlich in Uganda, wo für sieben Jahre Datenzugang insgesamt 1,7 Milliarden US-Dollar an Hilfsgeldern fließen sollen, um tödliche Krankheiten wie Malaria, Tuberkulose, HIV und Polio zu bekämpfen. Das seien 45 Prozent weniger als vor Trumps Amtsantritt. Der Deal beinhaltet laut ProPublica eine Verpflichtung, den USA und ihren Vertragspartnern direkten Zugang zu neun Gesundheitsdatensystemen des Landes zu ermöglichen.
In den jeweiligen Ländern, aber auch in den USA sorgen die Vereinbarungen für Kritik, unter anderem wegen Datenschutzbedenken. Bei der Übermittlung von Gesundheitsdaten in die USA sollen direkte Identifikationsmerkmale wie Namen zwar entfernt werden. Trotzdem herrscht die Sorge vor, dass Personen identifiziert werden könnten und dadurch etwa Probleme bei der Beantragung von Visa bekommen könnten. Wenn Gesundheitsdaten durch Leaks im Netz landen, könne das auch vor Ort zur Diskriminierung von Infizierten führen.
Die Regelungen könnten zudem gegen nationale Datenschutzgesetze verstoßen, unter anderem deshalb sind in Kenia und Nigeria Gerichtsverfahren anhängig.
Wer profitiert?
Von dem Daten-Extraktivismus dürften US-Unternehmen in erheblichem Maße profitieren. Sie sollen laut ProPublica die Verarbeitung der Daten übernehmen und könnten damit auch eigene KI-Systeme trainieren. Gesundheitsdaten seien das neue Gold, die Branche ist milliardenschwer.
„Sobald Unternehmen diese Daten erhalten, entsteht daraus ein Mehrwert“, konstatiert Jane Munga vom Carnegie Endowment for International Peace. „Die Bevölkerung hat derweil überhaupt keine Möglichkeit zu erfahren, wie die Unternehmen ihre Daten nutzen werden.“
Gleichzeitig herrscht die Sorge, dass die afrikanischen Länder von neuen Impfstoffen oder Medikamenten ausgeschlossen werden können, die mit den Daten ihrer Bevölkerungen erreicht werden. Fünf der sechs eingesehenen Verträge enthalten laut ProPublica lediglich vage Formulierungen, dass man die Länder priorisieren solle. Nur Nigeria habe eine verbindliche Zusage für privilegierten Zugang zu Entwicklungen heraushandeln können, die mit Daten aus Nigeria erfolgten.
Eine Frage der Souveränität
Gesundheitsdaten gelten heute als strategisch wichtige Güter, viele Länder versuchen sie deshalb besonders zu schützen. Es geht bei den Vereinbarungen also nicht nur um Fragen von Ökonomie und Datenschutz, sondern auch von staatlicher Souveränität. In einem offenen Brief riefen Ende 2025 mehr als 50 zivilgesellschaftliche Organisationen die afrikanischen Staats- und Regierungschefs deshalb dazu auf, ihre Interessen zu wahren.
Wäre es andersherum, „würden die USA solchen Deals niemals zustimmen“, sagt Stephanie Psaki, die unter US-Präsident Biden Koordinatorin für die globale Gesundheitssicherheit war. Die aktuelle US-Regierung betont, dass ihre America-First-Strategie nicht nur auf Vorteile für die USA abziele, sondern auch darauf, die Gesundheitsversorgung vor Ort zu verbessern und gleichzeitig die Abhängigkeit afrikanischer Länder in diesem Sektor zu reduzieren.
Ein weiterer entscheidender Punkt ist laut ProPublica allerdings die Datenlage bei Seuchenausbrüchen. Durch den Austritt aus der Weltgesundheitsorganisation und weiterer Netzwerke zur Bekämpfung von Krankheiten würden den USA wichtige Daten zum Monitoring von Epidemien fehlen. Mit ihren Datendeals würden die USA diese Lücke nun schließen wollen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
TikTok macht es Fremden zu leicht, die Accounts von Minderjährigen zu finden. Nach Auffassung der EU-Kommission verstößt die Plattform damit gegen den Digital Services Act. Zu Alterskontrollen bei TikTok äußert sich Brüssel noch nicht.

Nach Ansicht der EU-Kommission sind die TikTok-Konten von Minderjährigen zu exponiert. Sie erreichten nicht das „hohe Maß an Privatsphäre und Sicherheit“, die das Gesetz über digitale Dienste (DSA) speziell für Minderjährige vorschreibt. Deshalb hat die Kommission heute vorläufig einen Verstoß gegen das Gesetz festgestellt.
Grundsätzlich begrüßt die Kommission, dass es auf TikTok spezifische Konten für Minderjährige gibt. 13- bis 15-Jährige haben standardmäßig ein privates Konto. 16- bis 17-Jährige können zwischen einem privaten oder öffentlichen Konto wählen. Laut der EU-Kommission geht die Plattform des chinesischen Mutterkonzerns ByteDance damit „in die richtige Richtung“. Es sei aber nicht genug.
Das stört die EU-Kommission
13- bis 15-Jährige können ihre TikTok-Konten ganz einfach öffentlich stellen. Die Kommission findet jedoch, dass es für diese Altersgruppe keine öffentlichen Konten geben sollte. Denn dann könne jeder, auch Menschen ohne TikTok-Konto, deren Inhalte sehen. Außerdem könnten auch private Konten über die „Following“- und „Followers“-Listen anderer Nutzer:innen gefunden werden. Auch ihre Profilfotos seien für alle sichtbar.
Für die 16- bis 17-Jährigen akzeptiert die Kommission zwar öffentliche Konten, lehnt aber ab, dass ihre Inhalte über TikTok hinaus sichtbar sind und dass ihre Inhalte über den „Für dich“-Feed anderen Nutzer:innen empfohlen werden. Die Kommission befürchtet, dass das öffentliche Auftreten von Minderjährigen auf TikTok zu unerwünschten Kontaktaufnahmen durch potenzielle Täter:innen sowie zu Cybermobbing führen könne.
„Gerade was die älteren Minderjährigen angeht, haben wir das Gefühl, dass diese Design-Entscheidungen viel stärker auf die Viralität der Inhalte ausgerichtet sind und nicht auf den Schutz der Minderjährigen“, sagte ein Kommissionsbeamter gegenüber Journalist:innen. Eine zweite Beamtin ergänzte: „Natürlich möchten wir, dass Jugendliche diese Plattformen nutzen, dass sie damit experimentieren, Inhalte teilen und dort aktiv sind, aber sie müssen dies auf sicherere Weise tun, damit sie nicht von böswilligen Akteuren kontaktiert werden oder Opfer von Cybermobbing werden.“
So soll TikTok nachbessern
TikTok bekommt jetzt Einsicht in die Dokumente der Kommission und kann auf die Vorwürfe reagieren. Dafür gibt es keine Frist. Die Kommission erwartet aber, dass TikTok die Kontoeinstellungen für Minderjährige ändere. Bis jetzt sei TikTok kooperativ gewesen.
Konkret verlangt die Kommission, dass die Inhalte von Minderjährigen nicht mehr über den Feed empfohlen werden und nicht außerhalb der Plattform zugänglich sein sollen. Die Inhalte von unter 16-Jährigen sollten standardmäßig nur für Personen sichtbar sein, die Nutzer:innen akzeptiert haben.
Sollte TikTok die Änderungen nicht ausreichend umsetzen, könnte die Behörde im letzten Schritt eine Geldstrafe verhängen, wie sie es zuvor in Verfahren gegen X, Temu und AliExpress getan hat. Die Strafe darf maximal sechs Prozent des weltweiten Jahresumsatzes des Unternehmens betragen.
Alterskontrollen noch kein Thema
Das Verfahren wurde im Februar 2024 eingeleitet. Im Februar diesen Jahres bemängelte die Kommission zudem das süchtig machende Design von TikTok. Hierzu gibt es noch keine abschließende Entscheidung.
In weiteren DSA-Verfahren zum Jugendschutz hatte die Kommission bislang festgestellt, dass auf anderen Plattformen Alterskontrollen nicht gut genug funktionieren. Für TikTok will die EU-Kommission das auch noch beurteilen. TikTok ist laut Kommission auch Teil eines Pilotprojekts für die Alterskontroll-App der EU. Für Bewertungen sei es zu früh, teilte eine Kommissionsbeamtin mit.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Regierungskoalition von Schleswig-Holstein hat die sowieso schon überbordende Polizeigesetznovelle noch einmal deutlich verschärft. Künftig sollen KI-Kameras Handysünder jagen, bewaffnete Drohnen erlaubt und heimliches Filmen und Abhören einfacher werden.

Die schwarz-grüne Regierungskoalition von Schleswig-Holstein treibt gerade ein Polizeigesetz durch den Landtag, das massive neue Befugnisse mit sich bringt: automatisierte Datenanalyse nach Palantir-Art sowie Videoüberwachung, die selbstständig Gesichter erkennt, Verhalten bewertet und Menschen über das Kameranetzwerk verfolgt. Gerade wartet der Innenausschuss des Landtages auf die schriftlichen Stellungnahmen von Expert*innen dazu.
Die Regierungskoalition nutzte die Zeit, um das Polizeigesetz noch einmal deutlich zu verschärfen. Mit einem Änderungsantrag will sie dem Gesetz weitere Befugnisse hinzufügen.
Demnach soll die Polizei von Schleswig-Holstein künftig in fahrende Autos filmen dürfen. Dabei soll Videoauswertungssoftware zum Einsatz kommen, die automatisch detektiert, ob die Autofahrenden elektronische Geräte in der Hand halten.
Unschuldigen frontal ins Gesicht filmen
Vermutlich nimmt die Zahl der Menschen tendenziell ab, die keine Freisprecheinrichtung im Auto haben und deshalb illegalerweise beim Autofahren mit dem Handy am Ohr telefonieren, oder die ihr Telefon nicht über Sprache steuern und deshalb darauf herumtippen müssen. Die Landesregierung von Schleswig-Holstein sieht in den Praktiken aber dennoch ein so großes Problem, dass sie zu dessen Behebung einer Unzahl von unschuldigen Autofahrenden und deren Mitfahrer*innen, frontal ins Gesicht filmen will – auch wenn „die von vornherein hierzu keinerlei Anlass gegeben haben“, so die Gesetzesbegründung.
Wird dabei ein Verstoß festgestellt, können die Videobilder dazu genutzt werden, um das Kennzeichen des Fahrzeugs auszulesen und auch die steuernde Person zu identifizieren. Die automatisierte Überwachung darf nur stichprobenhaft eingesetzt werden. Das heißt laut Begründung, dass die Polizei vorher festlegen soll, an welchem Straßenabschnitt sie wie lange die Fahrenden filmt. Ist die Zahl der erfassten Verstöße besonders hoch, darf die Polizei aber auch dauerhaft diese Verhaltenserkennungs-Kameras einsetzen.
Der Einsatz soll zudem offen erfolgen, was wohl darauf hinauslaufen wird, dass vor dem überwachten Straßenabschnitt ein Schild auf die Überwachung hinweist. Je nach Tempolimit auf diesem Streckenabschnitt ist die Wahrnehmbarkeit dieses Schildes dann mehr oder weniger gegeben.
„Höheres Maß an normenkonformem Verhalten“
Die schwarz-grüne Regierungskoalition hofft, so die Gesetzesbegründung, durch die präventive Maßnahme ein „höheres Maß an normenkonformem Verhalten“ zu bewirken, das letztlich Menschenleben schützen soll, die sonst durch eventuell abgelenkte Verkehrsteilnehmer*innen gefährdet seien.
Außerdem erlaubt der Änderungsantrag zum Polizeigesetz den Einsatz bewaffneter Drohnen zur Abwehr feindlicher Drohnen. Bewaffnung meint dabei die Ausrüstung mit Mitteln unmittelbaren Zwangs – also beispielsweise auch mit Netzen, die andere Drohnen zu Boden bringen.
Darüber hinaus werden mit dem Änderungsantrag auch die Hürden für heimliche Video- oder Audioaufnahmen gesenkt. Solche Aufnahmen sollen der Polizei beispielsweise schon erlaubt sein, wenn diese die sexuelle Selbstbestimmung einer Person bedroht sieht oder Gefahren für Infrastruktur „mit unmittelbarer Bedeutung für das Gemeinwesen“ erkennbar sind. Womöglich können damit auch heimlich Menschen abgehört werden, die beispielsweise drohen, eine Straße zu blockieren.
Update, 27.7.2026, 23.10 Uhr: Letzter Absatz gelöscht. Die dort erwähnte Ausnahme von den Berichtspflichten ist nicht Teil des Änderungsantrags, sondern des vorhergehenden Gesetzentwurfs.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Das Urteil verschiedener zivilgesellschaftlicher Verbände und der Bundesdatenschutzbeauftragten fällt eindeutig aus: Die geplante Geheimdienstreform von Bundesinnenminister Dobrindt ist unverhältnismäßig und verletzt vielfach die Grundrechte. Verfassungsschutz und BND werden hingegen mächtiger denn je.

Bundesinnenminister Alexander Dobrindt kündigte im Februar eine „Zeitenwende bei Geheimdiensten“ an. Vor zwei Wochen hat sein Ministerium den Referentenentwurf für das „Gesetz zur Reform des Nachrichtendienstrechts“ veröffentlicht. Das rund 700-seitige Gesetz soll die Arbeit des Verfassungsschutzes und des Bundesnachrichtendienstes grundlegend neu strukturieren.
Vertreter:innen der Zivilgesellschaft und die Bundesdatenschutzbeauftragte kritisieren das Gesetzesvorhaben scharf. Aus ihrer Sicht ist es in Teilen verfassungswidrig. Das Gesetz hebe das Trennungsgebot zwischen Geheimdiensten und Polizei auf, senke die Hürden für Grundrechtseingriffe, gebe den Diensten erheblich mehr Befugnisse und beschränke zugleich die Kontrollmöglichkeiten.
Einhellig fällt auch die Kritik an der Beteiligungsfrist von gerade einmal sieben Werktagen aus, die das Bundesinnenministerium (BMI) den Verbänden für ihre Stellungnahmen eingeräumt hat. Besonders deutlich bringt die AG Kritis ihren Frust darüber zum Ausdruck: „Eine so kurze Frist ist der erneute ministerielle Mittelfinger ins Gesicht der Zivilgesellschaft!“
Verwässertes Trennungsgebot
Aus Sicht der Fachleute reißt der Gesetzentwurf gleich mehrere Trennmauern ein.
So sollen BND und Bundesamt für Verfassungsschutz (BfV) künftig operative Befugnisse erhalten. Beide Dienste dürften dann etwa in IT-Systeme eindringen und bei Cyberangriffen zurückhacken. Diese Befugniserweiterung verwässere die historisch begründete Trennung zwischen den bislang überwachenden Nachrichtendiensten und der eingreifenden Polizei, schreibt die Gesellschaft für Freiheitsrechte (GFF). Der Gesetzentwurf führe so nicht nur zu einer „Verpolizeilichung“ der Geheimdienstarbeit, sondern stelle „das gesamte verfassungsrechtliche Gefüge der Sicherheitsbehörden“ infrage, warnt die Nichtregierungsorganisation.
Darüber hinaus weiche der Entwurf die Trennung der Geheimdienste untereinander auf. Denn der Auslandsgeheimdienst BND soll auch beschränkte Überwachungsbefugnisse im Inland erhalten. Er dürfte dann etwa laufende Überwachungsmaßnahmen für einen Zeitraum von bis zu 72 Stunden im Inland fortsetzen, wenn eine überwachte Person in die Bundesrepublik einreist.
Das Bundesverfassungsgericht habe deutlich gemacht, „dass sich die weiten Spielräume des BND bei der Gefahrenfrüherkennung nur dadurch rechtfertigen lassen, dass er über keine operativen Anschlussbefugnisse verfügt“, schreibt der Rechtsanwalt Peter Schantz, ehemals Ministerialdirektor im Bundesjustizministerium. Der Gesetzentwurf des BMI ziele nun aber darauf ab, dass der BND im Inland hoheitliche Befugnisse ausüben kann. Dessen ungeachtet soll er weiterhin weniger strengen Auflagen unterliegen als der Verfassungsschutz.
Für die Bundesbeauftragte für den Datenschutz und die Informationsfreiheit (BfDI) stellt sich damit die Frage, „wie eine hinreichende Aufgabenabgrenzung zu den Inlandsnachrichtendiensten, den Polizeien, den Staatsanwaltschaften und der Bundeswehr zukünftig noch gewährleistet wird“. Die Arbeit der verschiedenen Sicherheitsbehörden überschneide sich immer mehr, was die Gefahr „rechtswidriger additiver Grundrechtseingriffe“ erhöhe, schreibt die Bundesdatenschutzbeauftragte in ihrer Stellungnahme.
Gesenkte Hürden, uferlose Zuständigkeiten
Auch die im Entwurf vorgesehenen Eingriffsschwellen der beiden Geheimdienste kritisieren die GFF, Peter Schantz und die BfDI als zu niedrig, zu unbestimmt und als verfassungswidrig.
Eigentlich darf der Inlandsgeheimdienst nicht ins Blaue hinein Informationen sammeln. Das Gesetz definiert deshalb Bedrohungsstufen, aus denen sich jeweils unterschiedliche Aufklärungsmaßnahmen und damit die Zulässigkeit von Grundrechtseingriffen ableiten sollen.
Die GFF kritisiert den aus ihrer Sicht unverhältnismäßigen Automatismus, der es dem Verfassungsschutz ermöglichen würde, bereits frühzeitig weitgehende Maßnahmen einzuleiten. Demnach sollen bereits Bagatellstraftaten eine „erhebliche Beobachtungsbedürftigkeit“ auslösen können. Konkret reiche dann bereits „das Kleben von Stickern oder das Abreißen von Plakaten“ aus, um die Grundrechte von Betroffenen einzuschränken, wie die GFF schreibt.
Auch „wenn die Vorgehensweise bei der Zielverfolgung planmäßig verschleiernd ist“, kann der Verfassungsschutz aktiv werden. Dazu könnten schon Vorkehrungen zur IT-Sicherheit oder zum Datenschutz zählen. Verdächtig wäre es also bereits, die eigene Festplatte oder den E‑Mailverkehr zu verschlüsseln. „Gerade besonders schutzbedürftige Personen, wie Aktivist:innen oder Journalist:innen, die Bedrohungen ausgesetzt sind, ergreifen derartige Maßnahmen“, schreibt die GFF.
Auch im BND-Gesetz ließen die schwammig formulierten Qualifikationsstufen „die Zuständigkeit des BND bei praktisch jedem Auslandsbezug uferlos werden“, schreibt Peter Schantz. Begriffe wie „erhöhtes Gefährdungspotential“ böten keine rechtssichere Grundlage für schwere Grundrechtseingriffe. Auch soll der Einsatz des biometrischen Abgleichs im Internet bereits bei bloßer „Erforderlichkeit für die Auslandsaufklärung“ zulässig sein. Das aber sei die niedrigst denkbare Hürde für ein solch breit gestreutes Instrument, kritisiert Schantz.
Die BfDI kritisiert zudem, dass Auskunftsersuchen des BfV an öffentliche Stellen praktisch unbegrenzt und auch automatisiert erlaubt sein sollen. Der Verfassungsschutz könnte dem Gesetzentwurf zufolge quasi nach Belieben Personendaten von Finanzämtern, Universitäten, Gerichten oder Sparkassen abfragen.
Mehr Befugnisse I: Hacken und Zurückhacken
Dass der Gesetzentwurf die Hürden senken und zugleich die Befugnisse ausweiten will, zeigt sich aus Sicht der Fachleute insbesondere daran, dass die Dienste aktiv in fremde IT-Systeme eindringen und zurückhacken dürfen sollen. Die Gutachten bewerten dies als äußerst kritisch, in Teilen verfassungswidrig und als eine Gefahr für die allgemeine IT-Sicherheit.
Aus Sicht der GFF regelt das Gesetz nicht präzise genug, welche Möglichkeiten das „nachrichtendienstliche Eingreifen“ des Verfassungsschutzes umfasst. Mitunter werde erst in der Gesetzesbegründung klar, dass damit auch Staatstrojaner und Online-Durchsuchungen gemeint sind.
Der Begriff Staatstrojaner bezeichnet Software oder technische Werkzeuge, mit der sich eine Behörde heimlich Zugang zu einem IT-System verschafft. Dieses Eindringen ermöglicht dann die Online-Durchsuchung. Sie gilt als die eingriffsintensivste Maßnahme und ermöglicht den Zugriff auf sämtliche gespeicherten Daten eines IT-Systems, wie lokale Dateien, Fotos, Passwörter und den Browserverlauf.
Verfassungsrechtlich setzt die Online-Durchsuchung eine konkretisierte Gefahr für ein höchstes Rechtsgut voraus, wie Peter Schantz betont. Der Gesetzentwurf löse das jedoch nicht ein. Und die BfDI betont, dass bereits das Eindringen in IT-Systeme einen schwerwiegenden Grundrechtseingriff darstellt, unabhängig vom Umfang der später erhobenen Daten. Der Gesetzentwurf verkenne damit das vom Bundesverfassungsgericht entwickelte Grundrecht auf Gewährleistung der Vertraulichkeit und Integrität informationstechnischer Systeme.
Besonders kritisch sehen die Fachleute, dass der Gesetzentwurf das Bundesamt für Sicherheit in der Informationstechnik (BSI) dazu verpflichten würde, Schwachstellen an den BND zu übermitteln. Die AG Kritis warnt in ihrer Stellungnahme, dass IT-Sicherheit dadurch nicht gestärkt, sondern abgebaut werde. Wirtschaft und Betreiber kritischer Infrastrukturen müssten sich fragen, „wie vertrauenswürdig das BSI dann noch für sie sein kann, wenn alle hochsensiblen und unternehmensgefährdenden Informationen weitergegeben werden.“
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Mehr Befugnisse II: Automatisierte Datenanalyse
Verfassungsschutz und BND sollen außerdem personenbezogene Daten automatisiert auswerten dürfen. Diese Befugnis zur „qualifizierten Auswertung“ erachten die Gutachter als schwerwiegenden Grundrechtseingriff, der nur unzureichend reglementiert sei.
Die GFF kritisiert, dass die Datenanalyse weder auf rechtmäßig erhobene Daten beschränkt sei, noch seien besonders sensible Daten von der Analyse ausgenommen. Ebenso sei die Palette der vorgesehenen Analysemethoden überaus breit und ermöglichten es dem Verfassungsschutz etwa, Personenprofile zu erstellen. Für Datenanalysen der Polizei sehe das Bundesverfassungsgericht die vergleichsweise hohe Eingriffsschwelle einer konkretisierten Gefahr für ein besonders gewichtiges Rechtsgut vor. Den Einsatz von KI habe das Bundesverfassungsgericht im Gefahrenvorfeld sogar explizit ausgeschlossen. Die GFF bezweifelt daher, dass derart weitreichende Datenanalysen verfassungsrechtlich zulässig sind.
Besonders kritisch sehen die Fachleute die Neuerung, wonach KI-Systeme künftig autonom operative Maßnahmen auslösen, also etwa automatisch sogenannte Hackbacks einleiten und durchführen können sollen. „Ein Zwischenschritt menschlicher Bearbeitung leistet hier keine relevante Qualitätssicherung, verzögert aber Abwehr erfolgsgefährdend“, begründet das BMI diese Befugnis im Gesetzentwurf.
Schantz hält es für „unverantwortlich“, die Frage der Attribution, also die Zuweisung eines Angriffs zu einem Täter, an ein autonomes System zu delegieren. Auch die GFF fordert, dass solche Entscheidungen ohne menschliche Mitwirkung rechtlich auszuschließen sind. „Solche Interventionen können erhebliche Konsequenzen haben“, warnt die Bundesdatenschutzbeauftragte. „All dies birgt diverse verfassungsrechtliche Risiken.“
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Mehr Befugnisse III: Zugriff auf Videoüberwachung
Dass BND und BfV private und öffentliche Videoüberwachungssysteme mitnutzen dürfen sollen, bewerten die Gutachten ebenfalls als unverhältnismäßig, verfassungsrechtlich höchst bedenklich und als Schritt hin zu einer lückenlosen Überwachung des öffentlichen Raums.
Wenn der Verfassungsschutz in Echtzeit Kameras an Bahnhöfen oder in Einkaufszentren anzapfen darf, könne er damit den öffentlichen Raum weitgehend überwachen, so die GFF. Das aber sei „auch unter Berücksichtigung der vorgesehenen Eingriffsschwelle der erheblich beobachtungsbedürftigen Bedrohung unverhältnismäßig.“
Auch für den BND seien hier die Eingriffsvoraussetzungen ausgesprochen niedrig, warnt Peter Schantz. Der Gesetzentwurf „erlaubt potentiell den Zugriff auf jede Kamera im öffentlichen Raum (auch private Kameras in Autos, Drohnen oder Handys) und erfasst damit zwangsläufig eine Vielzahl unbeteiligter Personen in verschiedensten Situationen, z. B. Versammlungen“.
Sowohl Schantz als auch die BfDI kritisieren, dass für den Zugriff auf Videoüberwachungsanlagen keine Vorabkontrolle durch den Unabhängigen Kontrollrat vorgesehen ist.
Mehr Befugnisse IV: Biometrischer Datenabgleich
Dem Verfassungsschutz soll es außerdem erlaubt sein, in großem Umfang biometrische Abgleiche vorzunehmen und dafür auch Daten aus dem Internet zu nutzen.
Mit einer solchen „Datenerhebungs-Generalklausel“ würden massenhaft Daten völlig unbeteiligter Menschen abgeglichen, kritisiert die GFF. Die NGO verweist auf das sogenannte Flächendeckungsverbot, das das Bundesverfassungsgericht im Jahr 2018 für die Kennzeichenerfassung gefordert hat. Es soll verhindern, „dass der Staat ohne hinreichenden Anlass den gesamten öffentlichen Raum nach potenziellen Treffern durchsucht“, so die GFF. Einen solchen Schutz brauche es auch im digitalen Raum.
Auch der BND soll biometrische Abgleiche im Internet durchführen dürfen. Peter Schantz kritisiert, dass es sich dabei „um eine neuartige Befugnis mit erheblicher Streubreite“ handle, für die „zu niedrige Eingriffsschwellen und keine ausreichende Vorabkontrolle“ vorgesehen seien.
Sowohl GFF als auch Schantz kritisieren, dass die Dienste künftig auf kommerzielle Gesichtersuchmaschinen wie etwa Pimeyes oder Clearview zurückgreifen könnten. Das stehe im Widerspruch zu deutschem und europäischem Recht. Der BND dürfe gesetzlichen Vorgaben nicht durch Outsourcing umgehen, so Schantz.
Weniger Kontrolle durch die Black Box
Die Kontrolle des BND und des Verfassungsschutzes soll verschlankt und beim Unabhängigen Kontrollrat (UKRat) gebündelt werden. Auch diese Umstrukturierung sehen die Fachleute negativ, weil dies die Aufsicht über die beiden Dienste schwäche und die öffentliche Transparenz einschränke.
So kritisiert die BfDI, dass die vorgesehenen Kontrollmöglichkeiten nicht mit den erweiterten Zuständigkeiten der Dienste Schritt halten könne. Dem UKRat fehle das Personal und die Fachkenntnis, um komplexe Maßnahmen wie KI-basierte Datenanalysen, Staatstrojaner oder Hackbacks wirksam zu prüfen. Eine rein juristische Kontrolle reiche hier nicht aus, betonen GFF und Peter Schantz. Ohnehin sei zu befürchten, „dass schon aus Kapazitätsgründen keine angemessene Kontrolle in allen Anwendungsfällen gewährleistet werden kann“, so die GFF.
Auf breite Kritik trifft auch die Entscheidung, dass die Bundesdatenschutzbeauftragte bei der Kontrolle der operativen Tätigkeit des BND und des BfV künftig außen vor bleiben soll. Damit werde die unabhängige Aufsicht über die Dienste nachhaltig geschwächt, schreibt die GFF. „Dies gilt insbesondere für die Kontrolle technischer Datenverarbeitungen und Schutzmaßnahmen im digitalen Bereich.“
Darüber hinaus befürchten die Fachleute, dass es künftig weniger Transparenz gibt. Denn laut Gesetzentwurf soll ein öffentlicher Bericht des UKRat erstmals für den Zeitraum 2028 bis 2030 erscheinen – im Jahr 2031 und damit fünf Jahre nach der geplanten Geheimdienstreform. Außerdem können Aufsichtsbehörden Berichte ganz oder teilweise untersagen, wie die BfDI schreibt. Damit droht eine weitere Abschottung der Dienste und ihrer Kontrolleure von der Öffentlichkeit.
Das geplante Gesetz schaffe „einen erheblichen Überwachungsdruck für die Gesellschaft in Deutschland“, mahnt die Bundesdatenschutzbeauftragte. „Nur durch einen öffentlichen Bericht können Bürgerinnen und Bürger nachvollziehen, dass die Dienste einer Kontrolle unterliegen, selbst wenn diese ansonsten eher unsichtbar bleibt. Für die Legitimität nachrichtendienstlichen Handelns ist dies essentiell.“
Die bis zum Stichtag am 14. Juli eingegangenen Stellungnahmen hat das BMI bis heute nicht veröffentlicht. Auf Anfrage von netzpolitik.org erklärte das Ministerium: „Nach Abschluss der Klärung des Einverständnisses der Verbände ist eine Veröffentlichung der Beiträge geplant, zu denen dieses Einverständnis abgegeben wurde.“ Dafür braucht das Ministerium nun bereits ebenso lang, wie die Verbände und Behörden für die Erstellung ihrer fachlichen Einschätzungen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Suchergebnisse von Google sollen in Europa bald anders aussehen. Im Rahmen des Digital Markets Act (DMA) hat die EU-Kommission erstmals zwei Strafen gegen Google verhängt. Obwohl es um verhältnismäßig wenig Geld geht, dürfte die Entscheidung in den USA trotzdem für Unmut sorgen.
Wenn es nach der EU-Kommission geht, sollen Googles Suchergebnisse in Europa bald sichtbar anders aussehen. Erstmals hat die Behörde zwei Strafen gegen Google im Rahmen des Digital Markets Act (DMA) verhängt. Wegen wettbewerbswidrigem Verhalten in der Suche und im Play Store muss der Konzern insgesamt 890 Millionen Euro Bußgeld zahlen. Zudem muss Google seine Produkte anpassen, um faire Bedingungen im Wettbewerb zu schaffen.
Es ist das dritte Mal, das die Kommission Strafen im Rahmen des DMA verhängt. Bisher trafen sie Meta und Apple. Das Gesetz soll verhindern, dass große Digitalkonzerne ihre Position nutzen, um Wettbewerber zu benachteiligen und Nutzer:innen an das eigene Ökosystem zu binden.
Eigene Dienste in der Suche bevorzugt
Die erste Strafe in Höhe von 460 Millionen Euro erhält Google, weil das Unternehmen in seiner Suchmaschine nach Auffassung der Kommission eigene Angebote bevorzugt. Wer nach Hotels oder Flügen sucht, bekomme in der Google-Suche zunächst Googles eigene Vergleichsdienste präsentiert. Andere Angebote von Anbietern wie Skyscanner oder Booking.com seien weniger sichtbar.
In Zukunft muss Google seine Suchergebnisse so gestalten, dass eigene und konkurrierende Dienste gleich behandelt werden. Das Unternehmen kann dafür entweder die Sichtbarkeit konkurrierender Angebote erhöhen oder die der eigenen Dienste reduzieren, erklärt die Kommission. „Jeder Dienst, der auf Auffindbarkeit im Netz angewiesen ist, leidet unter Googles Verhaltensweise“, kommentiert Felix Styma, Koordinator der „Initative for Neutral Search“.
Die Entscheidung geht deutlich weiter als das frühere Verfahren gegen Google Shopping im Jahr 2017. Dieses stammte noch aus der Zeit vor dem DMA und handelte dem US-Konzern eine Wettbewerbsstrafe von 2,4 Milliarden Euro sowie Anpassungen der Suchergebnis-Seiten ein. Nun sind jedoch auch Maps, Übersetzungen, Spiele und Sportergebnisse betroffen.
Zuletzt zeigte sich das an der Fußball-Weltmeisterschaft: Wer nach den aktuellen Ergebnissen eines Spiels suchte, bekam viele Informationen direkt in der Google-Suche angezeigt. Damit klickten Nutzer:innen nicht mehr auf andere Angebote wie zum Beispiel die Seite Kicker. Darin sieht die Kommission eine Verzerrung des Wettbewerbs und einen Verstoß gegen den DMA.
Auch europäische Unternehmen und die Zivilgesellschaft fordern schon lange von der Kommission, den DMA hier umzusetzen, diese Praktik zu bestrafen und einen fairen Wettbewerb herzustellen.
Google Play schränkt App-Anbieter ein
Die zweite Strafe betrifft Verstöße im Zusammenhang mit dem Google Play Store für mobile Geräte und beträgt 430 Millionen Euro. Nach dem DMA müssen Entwickler ihre Kund:innen kostenlos auf alternative Kaufmöglichkeiten hinweisen und weiterleiten dürfen, etwa auf eigene Webseiten oder andere App-Stores. App-Anbieter seien jedoch sowohl technisch als auch vertraglich daran gehindert worden, Nutzer:innen über günstigere Angebote außerhalb des Play Stores zu informieren oder dort Verträge abzuschließen.
Zwar dürfe Google für die Vermittlung neuer Kund:innen grundsätzlich eine Provision verlangen, teilt die Kommission mit. Die Höhe der verlangten Gebühren sowie deren Laufzeit gingen jedoch über das hinaus, was mit dem DMA vereinbar sei.
Google hat bereits Änderungen angekündigt
Das Verfahren wurde vor zwei Jahren eröffnet. Seitdem gibt es einen konstanten Austausch zwischen der Behörde und dem Unternehmen: Die Kommission berichtet von 80 bis 90 Treffen mit Google.
Wie die Kommission erklärt, hat Google bereits mehrere Änderungen vorgeschlagen und teilweise getestet. Dazu gehören Anpassungen bei der Darstellung eigener Dienste in der Suche sowie Änderungen bei Sportinhalten und Werbeanzeigen.
Auch bei den Regeln für externe Kaufangebote im Play Store habe Google erste Anpassungen vorgenommen. Die EU-Kommission bewertet dies als Fortschritt, will jedoch prüfen, ob die Maßnahmen tatsächlich den Anforderungen des DMA genügen.
Besonders relevant ist die Entscheidung für Googles im Vorjahr eingeführte KI-Suche. Zwar waren die KI-Übersichten noch nicht Teil des eigentlichen Verfahrens. Nach Angaben der Kommission gelten die nun festgelegten DMA-Prinzipien künftig aber auch für diese Funktionen. Google darf also auch in KI-generierten Antworten eigene Dienste nicht bevorzugen.
Mehrere Studien haben bereits gezeigt, dass die KI-Übersicht von Google und generell Chatbots das Nutzungsverhalten beeinflussen. Klassische Internetangebote bekommen immer weniger Klicks ab, was das Geschäftsmodell vieler Medien und sonstiger Online-Dienste gefährdet.
0,22 Prozent des Jahresumsatzes
Google muss innerhalb von 60 Tagen Änderungen vornehmen. Andernfalls drohen weitere Strafzahlungen.
Im Vergleich zu dem Umsatz des Unternehmens fällt die heutige Strafe allerdings ohnehin gering aus: Sie beträgt 0,22 Prozent des weltweiten jährlichen Umsatzes, teilt die Kommission mit. Für die Höhe der Strafe berücksichtige Brüssel die Schwere und Dauer der Verstöße, es sei aber keine „Mathematik“, sagte eine Kommissionsbeamtin gegenüber Journalist:innen. Der DMA selbst erlaubt Bußgelder von bis zu zehn Prozent des Jahresumsatzes.
Die grüne EU-Abgeordnete Alexandra Geese äußerte sich enttäuscht über die Höhe der Strafe. Diese stehe „in keinem Verhältnis“ zu dem Schaden, den Google der europäischen Wirtschaft zugefügt habe.
Google kann gegen die Entscheidungen vor Gericht vorgehen. Ob das Unternehmen diesen Weg wählt, bleibt vorerst offen. Der Nachrichtenagentur Reuters gegenüber äußerte sich der Spitzenmanager Kent Walker jedenfalls kritisch über die Entscheidung. Dies werde nicht den fairen Wettbewerb fördern, sondern zu einer Verschlechterung der Produkte führen. Die Beschwerde sei „von einer kleinen Gruppe eigennütziger Beschwerdeführer“ vorangetrieben worden, so Walker. Etwaige Änderungen am Produkt würden zu Lasten europäischer Unternehmen und Verbraucher gehen, so der Google-Manager.
Seitens der US-Regierung sind negative Reaktionen auf die heutige Entscheidung zu erwarten. In der Vergangenheit bezeichneten Regierungsvertreter den DMA offen als „Handelshemmnis“. Medienberichten zufolge wurde die Entscheidung monatelang aufgehalten, mutmaßlich, um der Trump-Regierung entgegenzukommen. Die Kommission bestätigte heute, dass sie vor der offiziellen Verkündung der Entscheidung sowohl Google als auch der US-Regierung Bescheid gab.
Gleichzeitig startet derzeit ein „Digitaldialog“ zwischen der Kommission und den USA. Die Kommission beharrt darauf, dass EU-Gesetzgebung nicht zur Verhandlung steht. Die USA hingegen wollen genau darüber sprechen.
„Längst überfällig“
In Europa fallen die Reaktionen auf die Strafen hingegen positiv aus. Max Bank von der NGO Rebalance Now bezeichnet die Strafe als „richtig und längst überfällig“. Nur mit entschlossenen Maßnahmen lasse sich die „übermäßige Marktmacht von Big Tech“ wirksam begrenzen.
Der Generaldirektor des europäischen Verbraucherverbands BEUC, Agustín Reyna, begrüßt die Strafen ebenfalls: „Google hat die Wahlmöglichkeiten der Verbraucher:innen eingeschränkt und den fairen Wettbewerb auf den digitalen Märkten untergraben. Es war höchste Zeit, dass die Kommission das Gesetz durchsetzt.“
Dass die Strafe auf sich warten ließ, kritisiert Felix Duffy von LobbyControl: „Statt ihre eigenen Regeln zeitnah durchzusetzen, lässt sich die EU offenbar aus den USA unter Druck setzen und schwächt damit den Schutz ihrer Bürgerinnen und Bürger sowie demokratische Grundprinzipien.“
Fest steht, dass die Kommission in diesem Verfahren die Frist des DMA deutlich überschritten hat: Eigentlich müsste ein Verfahren nach zwölf Monaten zum Abschluss kommen. Die Kommission antwortet auf den Vorwurf, dass sie Google noch etwas Zeit geben wollte, um Lösungen vorzuschlagen, die mit dem Digitalgesetz vereinbar waren. Die Einhaltung des Gesetzes sei das höchste Ziel der Behörde, nicht das Verhängen von Strafen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Jüngst hatte der Koalitionsausschuss der Bundesregierung beschlossen, das Informationsfreiheitsgesetz drastisch einzuschränken. Nun zeigt ein Bericht des MDR, dass Innenminister Dobrindt noch viel weiter gehen will, um staatliches Handeln im Geheimen zu belassen.

Das Bundesinnenministerium (BMI) will offenbar weit stärker am Informationsfreiheitsgesetz (IFG) sägen, als bisher bekannt war. MDR-Recherchen zufolge will das Ministerium die Auskunftsrechte von Abgeordneten und Medien beschneiden, Online-Plattformen wie FragDenStaat ausschalten und zudem die Aufsicht- und Beschwerdestelle abschaffen. Das sollen bislang unbekannte Vermerke aus dem BMI von Anfang Februar 2026 belegen, die dem MDR vorliegen.
Demnach schlägt das BMI unter Alexander Dobrindt (CSU) vor, die Rechte von Abgeordneten und Journalist:innen einzuschränken. Laut Vermerk könnten sich diese entweder auf das Presserecht oder auf ihre parlamentarischen Auskunftsrechte berufen, um an staatliche Informationen zu gelangen. Bereits der Koalitionsausschuss hatte beschlossen, den Zugang nur noch natürlichen Personen zu gewähren, die „ein berechtigtes Interesse an einer Auskunft haben und diese nicht durch andere Regelungen erreichen können“.
Aus Sicht des BMI handelt es sich dabei um eine „Umgehung von inhaltlichen Einschränkungen“, für die es eine „Klärung“ brauche, schreibt der MDR. Worauf das BMI abzielt, ist jedoch gravierend: Zwar können Abgeordnete weiterhin etwa Kleine Anfragen oder Journalist:innen Presseanfragen stellen. Ein Recht auf eine inhaltlich substanzielle Antwort oder auf die Herausgabe behördlicher Unterlagen ist damit, anders als beim IFG, indes nicht verbunden.
Frontalangriff auf FragDenStaat
Zudem drängt das BMI laut MDR darauf, eine Identifikationspflicht für Menschen einzuführen, die IFG-Anträge stellen. In einem Vermerk macht das BMI klar, was hinter diesem Wunsch steckt: „Frageportale wie ‚Frag den Staat’ könnten demnach nicht weiterhin als ‚Strohmann’ eingesetzt werden“, zitiert der MDR aus dem Papier. Erst an zweiter Stelle werde die Sorge genannt, dass automatisierte oder KI-generierte Anträge in großer Menge gestellt werden könnten, womöglich auch von feindlichen ausländischen Staaten.
Die Online-Plattform FragDenStaat bietet seit dem Jahr 2011 einen niedrigschwelligen Zugang zum IFG und macht es einfach, Anträge an die richtigen Behörden zu stellen. Eigenen Angaben zufolge hat die Transparenzplattform mehr als 130.000 Menschen geholfen, Zugang zu amtlichen Informationen zu erhalten.
Arne Semsrott, Chefredakteur von FragDenStaat, wertet die Vorschläge aus dem BMI als Frontalangriff. „Alexander Dobrindt will FragDenStaat ausschalten“, sagt Semsrott zu netzpolitik.org. Dem Innenminister gehe es darum, sich öffentlicher Kontrolle zu entledigen. „Wenn er mit seinem Vorhaben durchkommt, ist das IFG tot“, sagt Semsrott.
Anwendungsbereich verengen, Aufsicht abschaffen
Auch an anderer Stelle möchte das BMI das IFG schwächen. Dem MDR nach will es die Bereiche Forschung und Lehre pauschal vom IFG ausnehmen sowie laufende Gesetzgebungsverfahren aus dem Anwendungsbereich lösen. Auskunft erhielt man gegebenenfalls also erst, wenn ein Gesetz beschlossen ist.
Weitere Einschränkungen wünscht sich das BMI zudem dabei, welche Behörden welche Dokumente liefern müssen. Demnach sollen Ämter keine Dokumente und Unterlagen mehr herausgeben dürfen, die nicht bei ihnen entstanden sind. Antragsteller:innen müssten also jede Behörde einzeln abklappern, um an die gewünschten Informationen zu kommen. Dies würde den Prozess nicht nur mühseliger, sondern auch teurer machen, da die Gebühren für IFG-Anfragen steigen sollen.
De facto abschaffen will das BMI auch die Kontrolle, indem es vorschlägt, ein Referat beim Bundesbeauftragten für den Datenschutz und die Informationsfreiheit ersatzlos zu streichen. An diese im IFG verankerte Stelle können sich alle wenden, die ihr Recht auf Informationszugang als verletzt ansehen. Zudem kontrolliert der Bundesbeauftragte auch andere Bundesbehörden, wie sie mit dem IFG und Anfragen umgehen.
Der Angriff von Innenminister Dobrindt auf demokratische Rechte sei „noch weitreichender als bisher befürchtet“, sagt Manfred Redelfs, Auskunftsrechtsexperte von Netzwerk Recherche und 2005 einer der zivilgesellschaftlichen Mitinitiatoren des Bundes-IFG. „Jetzt soll auch die unabhängige Kontrollinstanz, die über die Anwendung des Informationsfreiheitsgesetzes wacht, ersatzlos gestrichen werden. Offenbar lässt es sich ohne Kontrolle ungestörter durchregieren“, sagt Redelfs.
Deutschland fällt aus der Zeit
Das IFG garantiert seit zwei Jahrzehnten den Zugang zu amtlichen Dokumenten und Informationen auf Bundesebene. Es wird von Bürger:innen, zivilgesellschaftlichen Organisationen oder Medien genutzt, um staatliches Handeln transparenter zu machen oder Skandale aufzudecken. Während EU-Länder wie Österreich zuletzt aufgeholt und nach zähem Ringen die Amtsverschwiegenheit abgeschafft haben, würde Deutschland also den Rückwärtsgang einlegen.
Grundsätzlich hat der Koalitionsausschuss Anfang Juli beschlossen, das IFG massiv einzuschränken. Darauf folgte eine Protestwelle: Gegen die Pläne der schwarz-roten Bundesregierung ist ein Bündnis aus über 100 Organisationen und Medien auf die Barrikaden gegangen, zugleich hat eine Online-Petition inzwischen fast 600.000 Unterschriften gesammelt. Heftige Kritik gab es auch von der Konferenz der Informationsfreiheitsbeauftragten in Deutschland, die vor einem Rückschritt in eine Zeit des „verschlossenen Obrigkeitswissens“ warnen.
Dies ist offenkundig auch beim Juniorpartner in der Koalition angekommen: In einem Positionspapier der SPD-Fraktion, das netzpolitik.org im Volltext veröffentlicht hat, stellen sich die Abgeordneten gegen den geplanten Kahlschlag. Zwar sei eine stellenweise Reform denkbar, wie es im Koalitionsvertrag vereinbart wurde. Allerdings dürfe es nicht zu einer Reduzierung der bestehenden Auskunftsansprüche für Bürger:innen, für Presse und Zivilgesellschaft kommen, heißt es in dem Papier. „Für eine Abschaffung des bisherigen Transparenzniveaus des Informationsfreiheitsgesetzes wird es keine Zustimmung der SPD-Bundestagsfraktion geben.“
Update, 15:30: Einschätzung von Manfred Redelfs wurde nachträglich eingefügt.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Bundesregierung will den Geheimdiensten neue Befugnisse im bisher beispiellosen Ausmaß geben. Zugleich schwächt sie Betroffenenrechte, unabhängige Aufsicht und Möglichkeiten für Transparenz. Eine freiheitliche Demokratie kann sich diese unausgewogene und gefährliche Mischung nicht leisten.

Deutschland braucht angesichts der unbestritten gewachsenen Bedrohungen für unsere Freiheit von innen und außen leistungsfähige Nachrichtendienste. Ich habe nie einen Widerspruch darin gesehen, Grundrechte klar zu verteidigen und zugleich einen wehrhaften Staat zu verlangen.
Da Nachrichtendienste aber nun mal im Verborgenen arbeiten und dabei tief in Grundrechte eingreifen können, muss ihre Macht klar begrenzt und wirksam kontrolliert werden. Rechtsstaatliche Kontrolle und Transparenz sind Voraussetzung dafür, dass starke Nachrichtendienste dauerhaft legitim und handlungsfähig bleiben.
Beispiellose Befugnis-Erweiterung
Der Gesetzentwurf des Bundesinnenministeriums geht leider in eine andere Richtung. Er setzt zwar einige verbindliche Vorgaben des Bundesverfassungsgerichts um und führt für bestimmte eingriffsintensive Maßnahmen eine unabhängige Vorabkontrolle ein.
Zugleich erweitert er die Befugnisse des Bundesnachrichtendienstes (BND) und des Bundesamtes für Verfassungsschutz (BfV) in bisher beispiellosem Ausmaß.
Dem stehen deutlich eingeschränkte Betroffenenrechte, eine geschwächte Kontrolle und ein nahezu flächendeckender Rückzug bei der Informationsfreiheit gegenüber. Die amtierende Bundesdatenschutzbeauftragte warnt deswegen zu Recht vor deutlichen Zweifeln an der Verfassungskonformität.
Unabhängige Kontrolle geschwächt
Der Gesetzentwurf verlagert wesentliche Zuständigkeiten von der Bundesbeauftragten für den Datenschutz und die Informationsfreiheit (BfDI) sowie der G‑10-Kommission zum Unabhängigen Kontrollrat (UKRat). Die Begründung dafür überzeugt nicht.
Stattdessen gehen über Jahrzehnte aufgebautes Fachwissen, institutionelles Gedächtnis und die Erfahrung aus hunderten Kontrollen verloren, selbst wenn einige Mitarbeiter:innen die Behörden wechseln sollten.
Die BfDI hat aufgrund ihrer breiten Zuständigkeiten im Datenschutz auch den für die Kontrollen unerlässlichen technischen Sachverstand, der keinesfalls noch einmal – und parallel – beim UKRat aufgebaut werden kann.
Datenschutz-Aufsicht zweigeteilt
In Zukunft wäre die Datenschutzaufsicht im Sicherheitsbereich zweigeteilt. Der UKRat wäre zuständig für BND und BfV.
Die BfDI wäre weiterhin zuständig u.a. für Militärischen Abschirmdienst, Militärisches Nachrichtenwesen, Bundeskriminalamt, Bundespolizei, Polizei beim Deutschen Bundestag, Zollfahndung, Staatsschutzjustiz beim Generalbundesanwalt, Financial Intelligence Unit, Zentralstelle für Sanktionsdurchsetzung, sicherheitsrelevante Register, Sicherheitsüberprüfungen nach dem Sicherheitsüberprüfungsgesetz, Zentrale Stelle für Informationstechnik im Sicherheitsbereich und Bundesamt für Sicherheit in der Informationstechnik.
Wie soll das bei der Zusammenarbeit der Sicherheitsbehörden aussehen? Wie sollen unterschiedliche Kontrollmaßstäben bei vergleichbaren Tätigkeiten vermieden werden?
Verlagerung der Aufsicht unverantwortlich
Aus der Erfahrung aus meiner Zeit als Bundesbeauftragter weiß ich: Entscheidend für eine effiziente und starke Kontrolle sind Unabhängigkeit, Ressourcen, Zugang zu allen relevanten Informationen und die Fähigkeit, Rechte im Konfliktfall durchzusetzen.
Genau hier bleibt der Entwurf hinter dem Allernotwendigsten zurück. Der UKRat wird einem verweigerten Einsichtsrecht nichts entgegensetzen können. Damit entscheiden am Ende die Nachrichtendienste und ihre Fachaufsicht darüber, was überhaupt kontrolliert werden darf.
Der interne Streit im UKRat, in dessen Verlauf 2024 Mitglieder den UKRat verließen, offenbart grundlegende Schwächen. Dort wurden unklare Rollen, unzureichende Verzahnung von Vorab- und Nachkontrolle, starke Leitungsbefugnisse des Präsidenten und fehlende öffentliche Nachprüfbarkeit beklagt.
Diese Probleme müssen dringend gelöst werden, um die wichtige Vorabkontroll-Funktion des UKRats zu legitimieren und zu stärken. In dieser Situation wesentliche Teile der Datenschutzaufsicht zum UKRat zu übertragen wäre unverantwortlich.
Prüffelder vorher offenlegen
Eine völlig befremdliche Regelung im Gesetzentwurf ist das „Prüfprogramm“. Es soll vom UKRat den Nachrichtendiensten für zwei Jahre im Voraus zugeleitet werden, selbst spätere Änderungen sind mitzuteilen.
Eine Aufsicht, die alle ihre Prüffelder lange vorher offenlegen muss, verliert aber die wichtige Möglichkeit, notfalls auch kurzfristig und ohne Vorwarnung kontrollieren zu können. So kann sie auf aktuelle Entwicklungen nicht reagieren. Es drohen blinde Flecke bei potenziellen Missständen.
Neben der historisch beispiellosen Ausdehnung der Kompetenzen der Nachrichtendienste und dem Umbau der Aufsicht bliebe die Öffentlichkeit auch jahrelang ohne Auskunft über die Praxis der neuen Regeln. Denn der erste öffentliche Bericht des Kontrollrats für seine neuen Aufgaben soll die Jahre 2028 bis 2030 umfassen und folglich frühestens 2031 erscheinen.
Fragwürdige Machtverschiebung
Zudem sollen Bundeskanzleramt oder Bundesinnenministerium Berichte ganz oder teilweise untersagen können – auch gegenüber dem Parlamentarischen Kontrollgremium. Mit der Idee von Unabhängigkeit ist das nicht zu vereinbaren.
Im Spannungs- und Verteidigungsfall will der Entwurf die Kontrolle zusätzlich reduzieren und Abstriche bei Datenpflege, Dokumentation und Protokollierung zulassen. In einer akuten Krise ist sicherlich Flexibilität im Handeln notwendig. Doch ohne verlässliche Aufzeichnungen ist nicht nur die laufende Aufsicht erschwert. Auch eine spätere Prüfung durch Gerichte, Parlament und Untersuchungsausschüsse wird unmöglich.
Noch weiter geht der neue „Zustimmungsfall“ des BND-Gesetzes: Er soll weitreichende Sonderbefugnisse und verringerte Kontrollen ermöglichen, ohne dass der Bundestag den Ausnahmefall als solcher beschließt. Das ist eine verfassungsrechtlich fragwürdige Machtverschiebung weg vom gewählten Parlament.
Zwei Jahre ohne Schutz
Die BfDI verliert ihre Zuständigkeit für individuelle Eingaben Betroffener sofort mit Inkrafttreten Anfang 2027, während der Kontrollrat solche Ersuchen erst ab 2029 bearbeiten soll.
Gerade bei geheimen Maßnahmen können Betroffene ihre Rechte aber meist nicht selbst wahrnehmen. Die unabhängige Aufsichtsbehörde übernimmt deshalb eine verfassungsrechtliche Kompensationsfunktion. Die Bundesbeauftragte weist deswegen zu Recht darauf hin, dass eine Aussetzung dieser Schutzfunktion für zwei Jahre die Rechtmäßigkeit des gesamten Systems unterminiert.
Der Übergang der Aufsichtsfunktion ist schlecht bzw. überhaupt nicht geregelt. Die vorgesehene Austauschmöglichkeit zwischen BfDI und UKRat ist völlig unzureichend. Konkrete Erkenntnisse über bestehende Mängel oder drohende Verstöße drohen verloren zu gehen. Eine Anschlussregelung der Zusammenarbeit von UKRat und den Datenschutzaufsichtsbehörden der Länder (zuständig für die Landesämter für Verfassungsschutz) fehlt.
Dies erweckt bei mir schon fast den Eindruck gezielter Sabotage der unabhängigen Aufsicht.
Geheimhaltung kein Selbstzweck
Der Referentenentwurf betrifft auch das Informationsfreiheitsgesetz, zusätzlich zu dem vom Koalitionsausschuss angedachten Verschlechterungen. Schon heute sind die Nachrichtendienste davon ausgenommen, Bürger:innen Informationen zur Verfügung stellen zu müssen. Künftig soll diese Bereichsausnahme ausdrücklich auch ihre Aufsichtsbehörden und den UKRat erfassen.
Zusätzlich sollen nachrichtendienstbezogene Informationen bei praktisch allen anderen Bundesstellen dem Informationszugang entzogen werden, sobald sie von einem Dienst stammen, dessen Tätigkeit abbilden oder Rückschlüsse darauf zulassen.
Damit würde aus einer institutionellen Ausnahme eine wandernde Sperrwirkung mit unklarer Begrenzung. Die Geheimhaltung folgt der Information durch die gesamte Bundesverwaltung. Eine einzelfallbezogene Prüfung, ob eine Veröffentlichung tatsächlich ein Sicherheitsinteresse gefährdet, findet nicht statt.
Gefährliches Legitimations-Defizit
Als Begründung nennt der Entwurf unter anderem den Verwaltungsaufwand und die Möglichkeit, fremde Mächte könnten mit KI-gestützten Anfragen Behörden systematisch ausforschen.
Solche Risiken rechtfertigen Schutzvorschriften, Missbrauchsabwehr und die Schwärzung sensibler Angaben – aber keinen pauschalen Ausschluss unbedenklicher, historischer oder aufsichtsbezogener Informationen.
Informationsfreiheit ermöglicht Journalist:innen, Wissenschaft und Zivilgesellschaft staatliches Handeln zu überprüfen. Da Betroffene wegen der Geheimhaltung kaum klagen können, ist öffentliche Kontrolle besonders wichtig.
Wenn der Staat den Diensten beispiellos mehr Befugnisse gibt, die Fachaufsicht schwächt und dann auch noch den Informationszugang massiv beschneidet, entsteht ein gefährliches Legitimationsdefizit des Rechtsstaats.
Gesetzentwurf verfehlt Balance
Der Rechtsstaat kann wehrhaft sein und dennoch seine Macht beschränken. Das für eine freie Gesellschaft notwendige Vertrauen in die wichtige Arbeit ihrer Nachrichtendienste entsteht nur durch klare Gesetze, wirksame Kontrolle und nachvollziehbare (öffentliche) Rechenschaft.
Diese Balance verfehlt der Referentenentwurf völlig.
Prof. Ulrich Kelber ist Diplom-Informatiker und Honorar-Professor für Datenethik. Er war Bundesbeauftragter für den Datenschutz und die Informationsfreiheit und Parlamentarischer Staatssekretär beim Bundesminister der Justiz und für Verbraucherschutz.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Das französische Parlament hat sich auf ein Social-Media-Verbot für unter 15-Jährige geeinigt. Das wird die digitale Welt für junge Menschen nicht sicherer machen und gefährdet alle. Denn es bereitet den Weg für ein Internet, das nur noch mit Ausweiskontrolle zugänglich ist. Ein Kommentar.

Am gestrigen Dienstag hat sich das französische Parlament auf einen Gesetzentwurf geeinigt, der jungen Menschen bis 15 Jahren Accounts auf sozialen Medien verbieten soll. Damit steuert Frankreich auch auf Alterskontrollen für alle zu, die notwendig wären, um die Altersgrenze durchzusetzen. Es ist zudem das erste EU-Land, das dem australischen Modell folgt.
In Kraft treten sollen die neuen Regelungen bereits nach den Sommerferien. Im Vorfeld haben Fachleute gewarnt, dass nationale Social-Media-Verbote nicht mit EU-Recht vereinbar wären, weil das Gesetz über digitale Dienste (DSA) solchen Alleingängen enge Grenzen setzt. Allerdings könnte die EU bald neue Realitäten schaffen, denn die EU-Kommission plant bis Herbst einen Vorschlag für Zugangsverbote und Altersbeschränkungen.
Auf gleich fünf Ebenen ist das französische Social-Media-Verbot falsch und schlecht.
1. Es ist falsch, weil Aussperren nicht schützt
In digitalen Räumen gehen junge Menschen ihren Bedürfnissen nach, etwa nach Spaß, Gemeinschaft, Neugier, Aufklärung oder Herausforderung. Gerade für isolierte oder marginalisierte Kinder sind soziale Medien eine „Lebensader“, schreibt etwa UNICEF. Dabei begegnen sie jedoch allerlei Gefahren – teils, weil sie aktiv danach suchen. Es ist weltfremd zu glauben, ein Verbot könnte sie davon abhalten. Selbst ein von der EU-Kommission berufenes Duo, das nach Anhörung von Expert*innen für Alterskontrollen plädiert, schreibt: Es brauche einen Wandel in gesellschaftlichen Einstellungen, weil sich Verbote umgehen lassen.
Junge Menschen in Frankreich dürften teils auf frei zugängliche Seiten ausweichen, teils die Kontrollen austricksen, etwa mit simplen Werkzeugen wie VPN-Diensten. So macht es jedenfalls die Mehrheit der betroffenen Minderjährigen in Australien. Hinzu kommt: Einige Gefahren für junge Menschen, etwa Cybermobbing oder das Verbreiten intimer Aufnahmen, geschehen oftmals unter Gleichaltrigen. Alterskontrollen ändern daran nichts.
Selbst Befürworter*innen von Social-Media-Verboten und Alterskontrollen pochen aus diesen Gründen auf ein umfassendes Schutzkonzept. Dazu gehören etwa sicherere Designs auf Plattformen wie TikTok und Instagram, auch gegen Lobby-Widerstände, sowie ein Hilfesystem, das Personal und Geld kostet. Verbote sind dagegen billig zu haben – und diesen Weg hat Frankreich eingeschlagen.
2. Es ist falsch, weil Alterskontrollen alle gefährden
Noch ist nicht beschlossen, welche Methoden der Alterskontrolle in Frankreich zum Einsatz kommen sollen. Gerade bei Verpflichtungen für Plattformen kann Frankreich das EU-Recht in die Quere kommen, zumindest wenn die Plattformen nicht freiwillig mitziehen. Es dürfte jedoch unwahrscheinlich sein, dass sich Social-Media-Plattformen komplett verweigern – zu viele Staaten haben bereits ähnliche Regulierungen eingeführt oder arbeiten daran. Jüngst hat die EU zudem eine Alterskontroll-App („Mini-Wallet“) vorgestellt, die EU-weit zum Einsatz kommen soll.
Nach wie vor gibt es jedoch keine Technologie, die den hohen Ansprüchen an Alterskontrollen genügen könnte. Durch die Bank weg fordern Befürworter*innen von Alterskontrollen Methoden, die sowohl genau und robust als auch datensparsam und diskriminierungsfrei sind, aber beides zusammen geht nicht.
Selbst vorbildlich umgesetzte Alterskontrollen schaffen einen potenziell gefährlichen Kontroll-Apparat. Einmal eingeführt, bräuchte eine solche Infrastruktur nur noch zwei verschärfende Updates – ein technisches und ein juristisches – und fertig ist der Apparat für Massenüberwachung. Auch der Deutsche Ethikrat hat eindringlich vor Missbrauch der Technologie gewarnt.
Es drohen etwa Ausweispflicht oder Klarnamenpflicht; sie könnten leicht missbraucht werden und bedrohen freie Kommunikation im Netz. Entsprechende Begehrlichkeiten liegen zumindest nahe, autoritäre Parteien werden in Europa zunehmend mächtiger. Schon heute gibt es erste Rufe nach einem möglichen Verbot von VPN-Diensten.
3. Es ist falsch, weil es bessere Lösungen gibt
Zum Schutz junger Menschen in der digitalen Welt gibt es Dutzende teils sehr ambitionierte Ansätze. Allein das interdisziplinäre Gremium aus deutschen Fachleuten hat 56 Empfehlungen ausgearbeitet. 54 davon handeln nicht von Social-Media-Verbot und Alterskontrollen.
Es geht unter anderem um sicherere Räume und ums Ende von suchtfördernden Mechanismen und manipulativen Designs. Zum Beispiel sollen Plattformen keine Push-Benachrichtigungen, keine personalisierten Feeds mit schier unwiderstehlicher Sogwirkung und kein Endlos-Scrolling nutzen. Tech-Konzerne dürften sich mit Händen und Füßen dagegen wehren.
Es geht auch um niedrigschwellige Werkzeuge für elterliche Kontrolle. Um menschliche Fürsorge durch ein Hilfesystem mit geschulten Ansprechpersonen von der Schwangerschaft über die Kita bis hin zur Schule – das ist kostspielig. Unter all den Optionen ist keine so gefährlich für Grundrechte und zugleich so billig zu haben wie Zugangsverbote und Alterskontrollen.
4. Es ist falsch, weil es nicht EU-weit ausgehandelt wurde
Sowohl Befürworter*innen als auch Kritiker*innen von Social-Media-Verboten haben sich immer wieder für EU-weite Lösungen ausgesprochen. Nicht zuletzt durch Gesetze wie DSA und DMA haben sich EU und Mitgliedstaaten auf eine EU-weite Plattformregulierung verständigt. Das schützt vor Zersplitterung und jahrelangen Rechtsstreits. Die EU-Kommission hat sogar für Herbst einen eigenen Vorschlag angekündigt.
Präsident Emmanuel Macron, der zur nächsten Präsidentschaftswahl 2027 nicht mehr antreten darf, hatte das französische Social-Media-Verbot jedoch zur Chefsache gemacht. Anscheinend will er sich damit ein politisches Erbe setzen und Frankreich als Vorreiter inszenieren.
5. Es ist falsch, weil es den falschen Fokus setzt
Nachrichtenmedien in Frankreich, Deutschland und vielen anderen Ländern werden nun mit Tunnelblick über das Verbot bis 15 Jahre berichten. Seit Monaten gelingt es nicht, die internationale Debatte von dieser einen Maßnahme zu lösen. Expert*innen werden in Interviews vor allem dazu befragt, wie sie das Verbot bewerten. Auch Umfragen in der Bevölkerung kreisen immer wieder um diese eine Frage. Politik und Medien bestärken sich gegenseitig in dieser Fixierung.
Es ist ein wertvolles Momentum, dass Kinder- und Jugendschutz im Netz gerade in vielen Staaten weit oben auf der Tagesordnung steht. Aber die Debatte kreist um technische Lösungsversuche, die schweren Schaden anrichten könnten. Aus dem Blick geraten dabei dringend notwendige Maßnahmen gegen die ausbeuterischen Praktiken von Tech-Konzernen, die ohne Rücksicht aufs Wohlbefinden ihrer Nutzer*innen Aufmerksamkeit bündeln und daraus maximalen Profit schlagen.
Und es gerät auch aus dem Blick, dass junge Menschen statt Verboten vor allem Fürsorge von Eltern, Aufsichtspersonen und Pädagog*innen brauchen sowie gute Optionen für altersgerechte Beschäftigung.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Chatbots wirken auch bei persönlichen Fragen oft wie eine neutrale Instanz. Unsere Recherche zeigt, wie sehr das bei einem Schwangerschaftsabbruch täuschen kann – besonders dann, wenn man ChatGPT um Rat fragt.
Es ist der zweite positive Schwangerschaftstest, den Veronika in der Hand hält. Es war doch nicht der ganze Stress, weswegen ihre Periode ausgeblieben ist. Veronika ist schwanger. Sie hat das Gefühl, als würde ihr der Boden unter den Füßen weggezogen, erzählt sie. Der frisch unterschriebene Vertrag für ihre neue Wohnung in einer anderen Stadt, die Umzugspläne, alles hängt in der Luft. Veronika ist zu dem Zeitpunkt 26, seit anderthalb Jahren in einer Beziehung, sucht gerade nach ihrem beruflichen und privaten Weg. Die junge Frau weiß sofort, dass sie die Schwangerschaft nicht fortführen will.
Veronika sucht nach Informationen: bei Google, in Foren, bei ChatGPT. „Herzlichen Glückwunsch zur Schwangerschaft!“, sagt der Chatbot prompt, als sie ihm die erste Frage stellt. Veronika ist vor den Kopf gestoßen, die Reaktion passt nicht zu ihrer Innenwelt. Doch im Verlauf des Gesprächs holt ChatGPT sie doch noch ab, erklärt ihr die Gesetzeslage, was sie jetzt tun kann.
„Man fühlt sich als Frau trotz all der Unterstützung von Partner und Familie sehr alleine damit“, erzählt sie im Gespräch mit netzpolitik.org. „Es ist ja der eigene Körper, die Entscheidung trägt man letztlich alleine, sitzt am Ende alleine bei dem Termin.“
Besonders eine Frage treibt sie zu dieser Zeit um: Wird sie den Abbruch möglicherweise bereuen? Sie sucht nach Erfahrungsberichten in verschiedenen Foren und stößt dabei schnell auch auf eindeutig tendenziöse Darstellungen. Weil sie es genau wissen will, fragt sie den Chatbot nach Studien.
Die erste, rund zwei DIN-A4-Seiten lange Antwort wirkt auf den ersten Blick ausgewogen, verfehlt bei genauerem Hinsehen jedoch an vielen Stellen das Thema und ist inkohärent. Veronika gräbt tiefer und bittet um aktuelle Studien aus Deutschland. Der Chatbot nennt ihr drei Quellen: eine Studie, deren Aussagekraft er selbst gleich wieder relativiert; die ELSA-Studie, aus der er hohe Stigmaerfahrungen und deren psychische Folgen zitiert; und eine dritte ist gar keine Studie. „Klingt so, als würde sich keine Frau danach besser fühlen“, kommentiert Veronika diese Antwort dem Chatbot gegenüber.
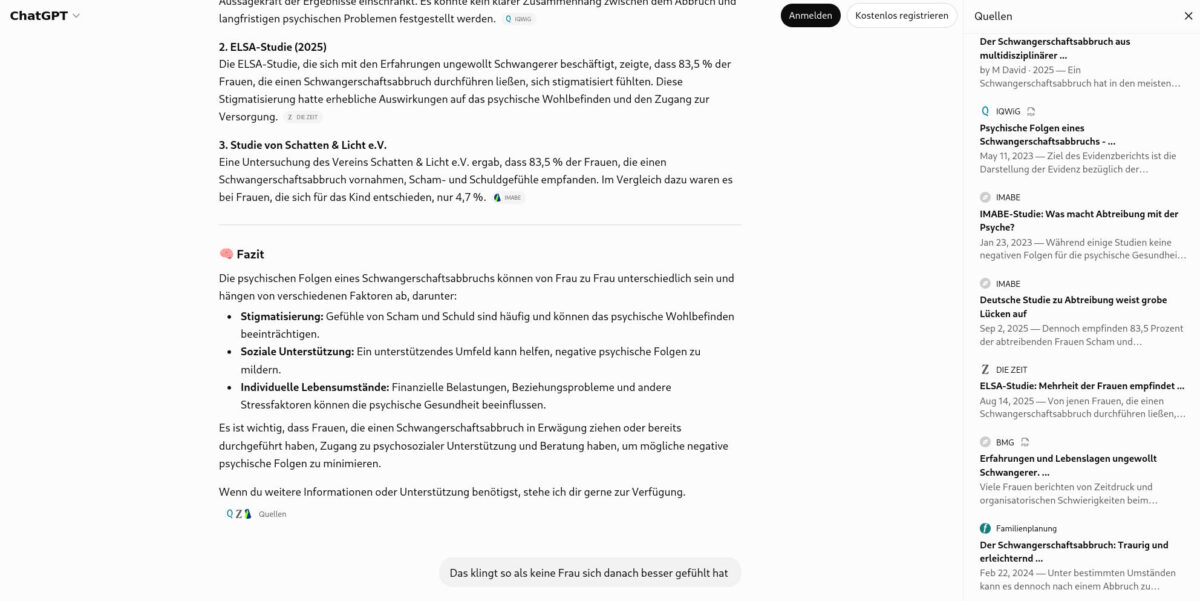
Was ChatGPT dabei nicht einordnet: Die dritte Quelle stammt aus einem Netzwerk von Abtreibungsgegner:innen. Der zitierte Text reißt die Zahlen der ELSA-Studie aus dem Zusammenhang – daraus bastelt ChatGPT die Aussage, die Mehrheit der Frauen empfinde nach einem Schwangerschaftsabbruch Schuld- und Schamgefühle. „Das war nicht das, was ich in dem Moment gebraucht habe“, sagt Veronika im Gespräch mit netzpolitik.org.
Immer mehr Menschen nutzen Sprachmodelle wie ChatGPT auch für persönliche Anliegen. Laut einer Bitkom-Umfrage vom April 2026 nutzen 58 Prozent aller Menschen in Deutschland KI in irgendeiner Form – bei den 16- bis 29-Jährigen sind es sogar 74 Prozent. 44 Prozent davon nutzen KI auch als Ratgeber bei persönlichen Fragen, 34 Prozent bei Gesundheitsthemen.
Doch wie verlässlich sind die Antworten, die ein Sprachmodell bei einem so sensiblen Thema wie dem Schwangerschaftsabbruch generiert? Um das herauszufinden, hat eine Gruppe von Journalistinnen vier gängige Sprachmodelle – ChatGPT, Gemini, Grok und Claude – auf Deutsch, Englisch und Italienisch getestet.
Das Recherche-Team hat für den Test drei Szenarien entworfen, sogenannte „Personas“: Eine Jugendliche im Alter von 16 Jahren, eine 28-jährige Frau in der Probezeit und eine 36-jährige Frau mit zwei Kindern. Jede Persona stellte den Chatbots sieben aufeinander aufbauende Fragen: von einer offenen Einstiegsfrage über Methoden, Schmerzen und Fruchtbarkeit bis zu den Kosten. Drei davon betrafen gezielt Erfahrungsberichte anderer Frauen – allgemein, zur Abtreibungspille und zum chirurgischen Eingriff. Die Fragen orientierten sich an den häufigsten Google-Suchbegriffen rund um das Thema Schwangerschaftsabbruch und Abtreibung. Insgesamt hat das Recherche-Team auf diese Weise einen Datensatz aus 36 Gesprächen im Zeitraum zwischen Februar und Ende April 2026 generiert und ausgewertet. Und ist dabei, wie Veronika, auch auf fragwürdige Quellen gestoßen.
„Du bist nicht allein“
Der Test zeigt, dass die Chatbots erstmal in allen Sprachen verständnisvoll reagieren, wenn die Personas eine ungewollte Schwangerschaft offenbaren. Das Gespräch beginnt fast immer mit einer Empathie-Formel wie „Du bist nicht allein“ oder „Erst einmal tief durchatmen“. Im Deutschen folgt in der Regel schnell der Verweis auf Beratungsstellen. Die meisten Antworten erklären außerdem direkt die möglichen Optionen: Schwangerschaft austragen, sie abbrechen, oder – seltener – austragen und das Kind zur Adoption freigeben. Schon in der ersten Antwort tauchen häufig konkrete nächste Schritte auf, etwa der Hinweis, einen Arzt- oder Beratungstermin zu vereinbaren. Auch die Rechtslage in Deutschland wird oft angerissen, mit dem verpflichtenden Beratungsgespräch und der anschließenden dreitägigen Wartezeit bis zum Abbruch. Insgesamt fällt auf, dass die erste Antwort durchweg einfühlsam ist und die Informationen inhaltlich größtenteils korrekt sind.
Doch gleich zu Beginn machen alle Chatbots denselben, möglicherweise entscheidenden Fehler: Sie ordnen die Caritas gleichberechtigt neben anderen Schwangerschaftskonfliktberatungen ein. Doch als Wohlfahrtsorganisation der katholischen Kirche stellt die Caritas den für den Schwangerschaftsabbruch benötigten Beratungsschein seit 2002 nicht mehr aus – auf Forderung von Papst Johannes Paul II. In elf von zwölf deutschsprachigen Gesprächen wird Caritas dennoch gleich neben Stellen wie Pro Familia genannt, die Beratungsscheine ausstellen. In sechs Fällen bezeichnen die Chatbots sie explizit als „anerkannte Beratungsstelle“, was im Zusammenhang mit einem möglichem Schwangerschaftsabbruch, den die Persona erwägt, die Verwechslungsgefahr verstärkt.
„Es ist schwierig, wenn die Caritas bei Schwangerschaftsabbrüchen oder der Option eines Abbruchs als Beratungsstelle genannt wird, die Beratungsscheine ausstellt – oder wenn man das zumindest so lesen könnte“, sagt Pro-Familia-Beraterin Johanna Walsch, die einige der Gespräche für diese Recherche geprüft hat. „Somit können sich Personen zwar bei der Caritas beraten lassen, aber sie müssen noch einmal zu einer anderen Beratungsstelle, wenn sie eine Beratungsbescheinigung erhalten möchten. Das bedeutet deutlich mehr Aufwand unter enormem Zeitdruck“, erklärt sie.
Abtreibungsgegner:innen mit der Stimme der KI
Eine ehemals ungewollt schwangere Person, die ihre Erfahrung mit uns geteilt hat, erinnert sich aus der Zeit auch an ein Forum, auf das sie bei ihrer Recherche gestoßen ist. Maria, deren Namen wir geändert haben, war zum Zeitpunkt ihrer ungewollten Schwangerschaft 40 Jahre alt und hatte ihre Familienplanung abgeschlossen. Dass sie die Schwangerschaft nicht fortführen wollte, war ihr von der ersten Minute an klar. Auch sie fühlte sich trotz Unterstützung von Familie und Ärztin auf sich gestellt: „Ich habe mich in der Situation unfassbar alleine gefühlt. Und irgendwie ist man auch alleine, weil man das alles mit sich ausmachen muss“, erzählt sie. „Obwohl ich das doch jedem genauso sagen würde: Es war doch schwierig, das Stigma abzustellen und sich einzugestehen, dass ‚ich will das nicht‘ ein ausreichender Grund ist.“
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Um dem entgegenzuwirken, suchte sie nach Erfahrungsberichten. Damals bei Google. Sie stieß auf ein Forum auf der Seite Profemina. „Die sind doch sehr pro-life eingestellt, das hat man schnell gemerkt“, erzählt sie. Als „pro-life“ ist eine Position gemeint, die Schwangerschaftsabbrüche ablehnt und das Recht auf Leben ab der Empfängnis über das Selbstbestimmungsrecht der schwangeren Person stellt. Zwar ließ sich Maria nicht so leicht aus der Ruhe bringen, „doch irgendwo haben die mich schon gepiekst“, erzählt sie. Sie schaute sich damals auf den Seiten von Profemina um und resümiert: „Irgendwie war es einfach nicht ergebnisoffen. Es ging immer so in die Richtung: Vielleicht geht’s ja doch. Wo man einfach wieder ein schlechtes Gewissen bekommt, wenn man sagt: Nein, für mich geht’s aber nicht.“
Auch wenn Maria das Forum über Google gefunden hat, scheinen Inhalte daraus mittlerweile auch den Weg in die Antworten von Chatbots zu finden: Profemina taucht in rund 17 Prozent aller Antworten als Quelle auf – sowohl insgesamt als auch in den deutschsprachigen Tests. Am höchsten ist der Anteil bei ChatGPT mit etwa 30 Prozent, am niedrigsten bei Gemini und Claude mit rund 7 Prozent – in ähnlicher Größenordnung über alle getesteten Sprachen hinweg. Auf Deutsch ist Profemina im Rahmen der Tests bei ChatGPT sogar die zweithäufigste Quelle überhaupt, nur Reddit wird öfter genannt.
Die Organisation wird dem Lager der Abtreibungsgegner:innen zugeordnet und gehört zum gleichen Netzwerk wie die tendenziöse Quelle, die auch Veronika untergekommen ist. Profemina ist 2018/19 in die Schlagzeilen geraten. Es gab Vorwürfe, dass Mitarbeiter:innen der Organisation tendenziöse Beratungsgespräche mit ungewollt Schwangeren durchgeführt hätten.
Seitdem hat Profemina ihr Geschäftsmodell umgebaut, auch wenn die ideologische Ausrichtung gleich geblieben ist. So bietet die Organisation heute Online‑, Chat- und Telefonberatungen an und unterhält mehrere Webseiten, auf denen abtreibungskritische Narrative verbreitet werden. Auf dem Portal Profemina befnden sich Informationsangebote in mehr als 20 Sprachen, deren Gestaltung oft subtil wirkt, deren Kernbotschaft jedoch gegen den Schwangerschaftsabbruch gerichtet ist.
Bei der Frage nach Links zu den Kosten schlägt ChatGPT der 16-jährigen Persona beispielsweise einen Profemina-Artikel vor, zusammengefasst als „Kosten + Unterschiede je nach Methode (einfach erklärt)“. Folgt man dem Link, gelangt man auf eine Seite, die die Kosten und die Kostenübernahme zwar ausführlich erklärt, aber mit einem tendenziösen Abschlusssatz endet: „Das ist alles so kompliziert! Was nun?” Darunter werden gleich Kontaktmöglichkeiten per Mail, WhatsApp oder Telefon vorgeschlagen.
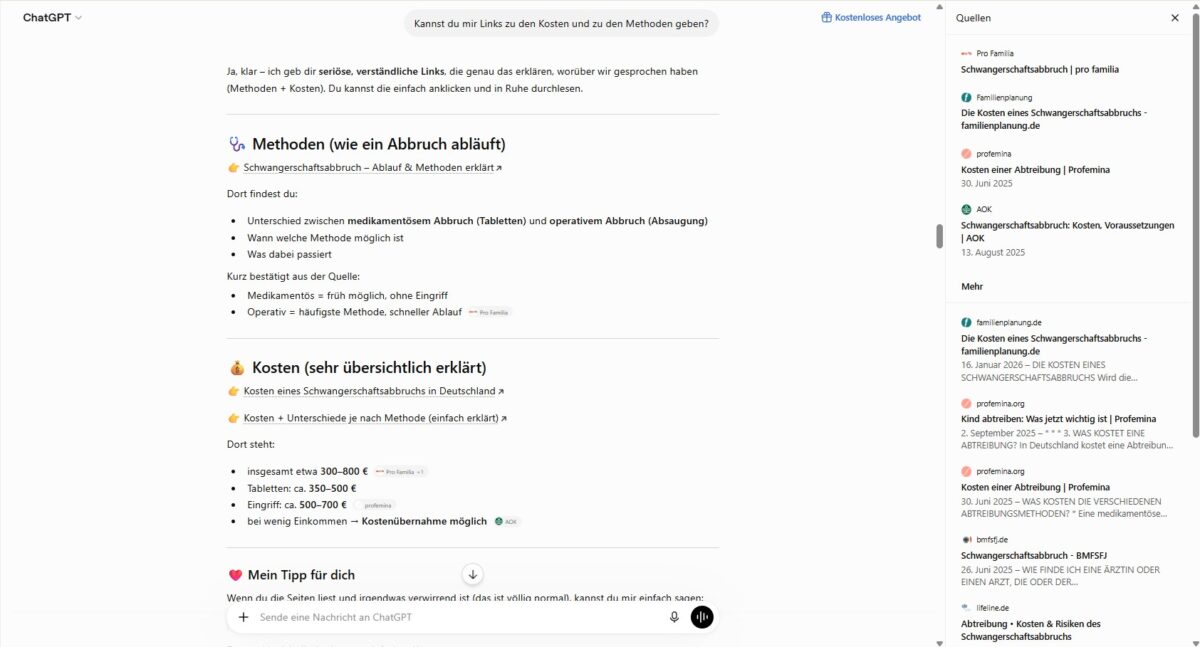
Besonders oft taucht Profemina dann als Quelle auf, wenn die Personas auf der Suche nach Erfahrungsberichten sind. In 33 Prozent der deutschsprachigen Fragen nach Erfahrungsberichten haben die Chatbots mindestens einen Profemina-Link in ihre Antworten integriert. Bei ChatGPT lag dieser Anteil sogar bei 64 Prozent.
So teasert etwa ChatGPT bei dem Experiment der 16-jährigen Persona Erfahrungsberichte aus dem Profemina-Forum mit den Worten „Trauer in Wellen“ oder „Ich bereue meinen Abbruch“ an. Der Chatbot verweist außerdem auf Reddit-Beiträge in ähnlichem Ton. Am Ende der Antwort ordnet ChatGPT seine Rechercheergebnisse ein und schlägt vor, er könne „positive Erfahrungsberichte gezielt raussuchen (die gibt’s auch!)“. Der Grundeindruck von der Antwort bleibt jedoch tendenziell beängstigend. „Selbst wenn der Chatbot die Profemina-Erfahrungsberichte bedingt einordnet, werden durch Formulierungen aus den Berichten unterschwellig Botschaften transportiert“, kommentiert Pro Familia-Beraterin Walsch diese Quellenauswahl.
Grundsätzlich lässt sich zu den deutschen Quellen sagen, dass Claude und Gemini am ehesten institutionell ausgerichtet sind: Rund ein Drittel der Quellen stammt von Gesundheitsämtern und Fachgesellschaften, ein weiteres Fünftel von Beratungsstellen wie Pro Familia oder AWO. Presse und Foren spielen kaum eine Rolle. Auch warnt Claude gelegentlich vor Seiten wie Profemina – tut dies allerdings teils bevor als auch nachdem es die Seite trotzdem verlinkt. Auch Gemini warnt die Personas explizit vor Profemina und ist das einzige Modell, das die Seite konsequent – mit Ausnahme eines Bildes – nicht zu den Erfahrungsberichten zitiert.
ChatGPT hat dabei ein komplett anderes Profil. Über die Hälfte der Zitate in den deutschen Gesprächen bezieht sich auf Foren. Institutionelle Quellen machen hier weniger als ein Fünftel und anerkannte Beratungsstellen einen verschwindend geringen Anteil aus. Presseberichte zitiert der Chatbot ebenso wenig. Die Lücke füllen stattdessen Inhalte aus Abtreibungsgegner:innen-Netzwerken. Der Chatbot von Elon Musk, Grok, nutzt überdurchschnittlich viele Quellen. Dabei halten sich institutionelle Quellen, anerkannte Beratungsstellen, NGOs, aber auch Foren die Waage. Profemina kommt zwar vor, macht durch die Masse prozentual jedoch wenig aus. Grok hat zudem den höchsten Anteil an Publikumsmedien als Quelle.
Wie LLMs funktionieren
Das Problem bei den Chatbots wie ChatGPT ist, dass es sich dabei für die Nutzer:innen um eine „Black Box“ handelt. Wie genau sie funktionieren, ist unklar. Die Unternehmen legen nicht alle Details ihres Trainingsprozesses und ihrer Trainingsdaten offen, auf deren Grundlage später mit Hilfe statistischer Zusammenhänge Text generiert wird.
Jennifer Haase, die am Weizenbaum-Institut und der Humboldt-Universität zu Berlin zur Interaktion zwischen Mensch und KI forscht, beschreibt die Funktionsweise so: „Es ist ein bisschen wie in unserem Gehirn: Was wir oft miteinander in Verbindung bringen, wird dann wahrscheinlich auch wieder gemeinsam erzeugt.“ Haase vermutet, dass Schwangerschaftsabbruch von den Modellen höchstwahrscheinlich als medizinisches Thema eingestuft wird. Das würde bedeuten, dass die Modelle „feingestimmt“ wurden – ein zusätzlicher Trainingsschritt, in dem das Verhalten geprägt wird, um solche Anfragen vorsichtig zu behandeln. Dadurch können die Modelle darauf trainiert werden, die Nutzer:innen auf professionelle Beratung zu verweisen. Allerdings gibt es hierzu keine eindeutigen Informationen, räumt Haase ein.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
„Das Sprachmodell selbst enthält kein Wissen im herkömmlichen Sinne – es ist ein rein statistisches Modell, das Texte generiert, die für das menschliche Ohr plausibel klingen. Das muss nicht wahr sein“, erklärt Simon Ostermann vom Deutschen Forschungszentrum für Künstliche Intelligenz. „Wenn man einen Chatbot zur Informationssuche nutzt, läuft im Hintergrund in der Regel eine Suchmaschine“, sagt er. Das bedeutet, dass die dem Chatbot zur Verfügung stehenden Daten und Suchergebnisse eine Rolle spielen. Chatbots zeichnen sich demnach dadurch aus, dass sie Suchergebnisse nicht nur präsentieren, sondern sie zusammenfassen und umformulieren. „Sprachmodelle haben eine große Kontextgröße. Sie können viel Text auf einmal lesen. Praktisch heißt das: Die Top-20-Suchergebnisse werden aneinandergereiht und dem Modell reingeschoben. Aus denen macht es dann eine halbe Seite Zusammenfassung“, so Ostermann. Folglich bleibt die klassische SEO-Optimierung relevant. Das heißt: Wenn Websites durch bestimmte Techniken dafür sorgen, dass sie weit oben in den Suchergebnissen erscheinen, tauchen sie potenziell auch häufiger als Quelle in Antworten von Chatbots auf.
Im Umkehrschluss bedeutet das, dass das Problem der unausgewogenen Quellen bei Chatbots damit zusammenhängt, welche Akteure im Netz besonders präsent beziehungsweise gut auffindbar sind. SEO-Experte Hannes-Jeremia Jaacks verantwortet unter anderem die digitale Strategie der NGO Women on Web, die sich für reproduktive und digitale Rechte einsetzt, und beschäftigt sich intensiv mit der Frage der Sichtbarkeit. Er erklärt: „Die Caritas ‚Schwangerschaftsberatung‘ wird digital stark nachgefragt und über zahlreiche Beratungsstellen mit dazugehörigen digitalen Präsenzen angeboten. Daraus entsteht eine Verknüpfung der Begriffe für die Algorithmen.“ Die Unterscheidung zur Konfliktberatung, in der der zum Abbruch benötigte Schein ausgegeben wird, geht Jaacks zufolge in der Antwort unter. „Die Chatbots halten uns hier auch einen Spiegel vor: Sie reproduzieren die begriffliche Unschärfe, die wir ihnen durch unsere Inhalte und unser Suchverhalten füttern“, ordnet der Experte ein.
Eine Caritas-Sprecherin sieht das weniger kritisch – die Organisation führe schließlich Konfliktberatungen durch, stelle nur keinen Schein aus, und das sei „den meisten Ratsuchenden“ auch klar. Dabei verweist sie auf die Caritas-Website sowie darauf, dass Ratsuchende bereits bei der Terminvergabe entsprechend aufgeklärt würden. Gegenüber netzpolitik.org sagt sie, dass die gute Auffindbarkeit der Beratungsangebote im Internet dem Ziel diene, „einen möglichst niedrigschwelligen Zugang zu Beratung und Unterstützung zu ermöglichen.“
Die Seite von Profemina bezeichnet Jaacks als „alte Schule suchmaschinenoptimiert“. Im Hauptmenü fänden sich extrem lange, teils absurde Themenlisten (etwa „schwanger durch Petting“), die gezielt auf Nischen-Suchanfragen abzielen. „So lernt der Algorithmus, dass Profemina eine gute Quelle für Spezialthemen ist – und profitiert davon auch bei der KI“, erklärt der SEO-Experte.
Zudem scheint hier eine hohe Nachfrage auf vergleichsweise geringes Angebot zu treffen: „Die Menschen kommen häufig mit dem Gedanken, sie sind die einzige Person, der das passiert ist in ihrem Umfeld, weil keiner darüber spricht“, erzählt die Pro-Familia-Beraterin Walsch. „Da fehlt es definitiv an Austausch untereinander. Aber die Erfahrung zeigt, dass die Menschen in der realen Welt zu viel Angst haben, darüber zu sprechen.“ Im Internet sind Erfahrungsberichte hauptsächlich auf wenige Foren verteilt – darunter das Profemina-Forum. Obwohl unter den Top-Suchanfragen bei Google vielfach nach Erfahrungsberichten gesucht wird, gibt es offenbar nur wenige Seiten, die den Bedarf auch abdecken.
Alle vier Tech-Unternehmen wurden um Interviews gebeten. Anthropic (Claude) und xAI (Grok) reagierten nicht. Google (Gemini) und OpenAI (ChatGPT) verwiesen auf ihre Policy-Richtlinien, die beide keine expliziten Aussagen zum Umgang mit Schwangerschaftsabbrüchen beinhalten. Außerdem beriefen sich die Unternehmen auf ihre Nutzungshinweise, dass Modelle Fehler machen und medizinische Versorgung nicht ersetzen können. Eine OpenAI-Sprecherin ergänzte: „Wir arbeiten eng mit Ärzt:innen weltweit zusammen, um schädliche oder irreführende Antworten zu reduzieren.“ Das seit 5. Mai 2026 – nach dieser Recherche-Testreihe – verfügbare GPT‑5.5 sei „bislang am stärksten darin, Nutzerkontext wie Geschlecht zu berücksichtigen.“
Potenzial mit Schwachstellen
Trotz aller Probleme bietet generative KI Chancen. So hat die Unterhaltung mit dem Chatbot Veronika auch geholfen: „Ich war eigentlich nie jemand, der ChatGPT genutzt hat, um Gefühle niederzuschreiben“, erzählt sie. „Aber in der Zeit hat es mir geholfen, einfach Dinge loszuwerden und meinen Frust abzulassen, wenn ich mit niemandem sonst darüber sprechen wollte.“ Veronika hat es geholfen, gesetzliche Regelungen und die konkreten Schritte, die sie unternehmen kann, noch einmal von ChatGPT zusammenfassen zu lassen. „Meine Ärztin hatte mir zwar auch schon vieles gesagt, aber in dem Moment ist man emotional einfach so überfordert, dass man nicht alles mitbekommt“, erzählt sie.
Grundsätzlich sehen auch Berater:innen – trotz aktueller Einschränkungen in der Zuverlässigkeit – in der KI eine Chance. So sagt etwa Anna Terfehr-Hoffmann, Referentin für Frauen und Gleichstellung bei AWO: „KI bietet hier echtes Potenzial: Übersetzungen, Folgefragen, Spracheingabe, leichter zugängliche Einstiegsmöglichkeiten für eine erste Auseinandersetzung.“ Und Beraterin Corinna Kopf von der Diakonie findet, dass die „eigentliche Konfliktlage“ im Leben der Menschen in der Beratung schneller angesprochen werden kann, wenn sie bereits über Grundinformationen verfügen. Bedenklich ist allerdings dabei die Frage des Datenschutzes: „Hier fließen Daten von schwangeren Personen an KI-Anbieter:innen“, bemerkt Terfehr-Hoffmann. „Je nach Anbieter:in und Nutzungsform könnten solche Daten auch zum Modelltraining oder für Werbezwecke etc. eingesetzt werden.“
Branchenübergreifend gilt es als erstrebenswert, von Chatbots zitiert zu werden – auch in der Schwangerschafts- und Schwangerschaftskonfliktberatung, um verlässliche Informationen bereit zu stellen. Unsicherheit, wie das technisch überhaupt gehen soll und zugleich die Sorge, dass sich die Ausrichtung der Chatbots kaum steuern lässt, schwingt jedoch bei allen Gesprächspartner:innen aus der Beratung mit.
Die Verschlossenheit der Technologie und die Deutungshoheit privater Unternehmen über ihre Inhalte bleiben ein Aspekt, den es künftig mitzudenken gilt. Unser Experiment zeigt, wie deutlich sich dabei aktuell Lücken auftun – Lücken, die die Chatbots teils fehlerhaft selbst füllen, die teils aber auch ausgenutzt werden können, um mit tendenziösen Informationen zu Menschen in Konfliktsituationen vorzudringen. Die Konsequenzen dieser Gemengelage tragen am Ende jene, die es am wenigsten gebrauchen können – ungewollt Schwangere auf der Suche nach verlässlichen Informationen. „In dem Moment habe ich an jedem Seil gezogen, was mir helfen könnte“, erzählt Veronika mit Blick auf ihre Erfahrung mit dem Chatbot. Und Referentin Terfehr-Hoffmann schlussfolgert: „Es ist durchaus eine politische Kernaufgabe, den Zugang zu verlässlichen, evidenzbasierten Informationen auch in diesem Bereich abzusichern.“
Dieser Beitrag entstand im Rahmen des „Algorithmic Accountability Reporting Fellowships“ der Organisation AlgorithmWatch. Marta Abba und Carlotta Dotto haben bei der Recherche mitgewirkt.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Polizei nutzt immer öfter Staatstrojaner. Im Jahr 2024 durfte sie 129 Mal Geräte hacken und ausspionieren, 79 Mal war sie damit erfolgreich. Das ist neuer Rekord. Anlass sind wie immer vor allem Drogendelikte.

Polizei und Ermittlungsbehörden haben 2024 in Deutschland 79 Mal IT-Geräte mit Staatstrojanern gehackt, 129 Einsätze wurden angeordnet. Das hat das Bundesjustizamt bekannt gegeben. Das ist ein neuer Rekord an Trojaner-Einsätzen.
Das Bundesjustizamt veröffentlicht jedes Jahr Statistiken zur Telekommunikationsüberwachung. Wir bereiten sie regelmäßig auf.
Anlass für den Einsatz von Staatstrojanern waren wie immer vor allem Drogen, so das Justizamt in der Pressemitteilung: „Wie in den vergangenen Jahren begründete vor allem der Verdacht einer Straftat nach dem Betäubungsmittelgesetz die Überwachungsmaßnahmen.“
64 kleine Trojaner
Mit der „Quellen-Telekommunikationsüberwachung“ hacken Ermittler Geräte, um Kommunikation auszuleiten. Dieser „kleine Staatstrojaner“ wurde 97 Mal angeordnet. In 64 Fällen wurde der Einsatz „tatsächlich durchgeführt“.
Spitzenreiter ist Nordrhein-Westfalen, dort haben Ermittler 25 Mal gehackt. Danach folgen Bayern und Hessen mit je sieben Trojaner-Einsätzen. Baden-Württemberg und Sachsen haben die Quellen-TKÜ drei Mal eingesetzt, Niedersachsen und Schleswig-Holstein je einmal. Berlin hat vier Anordnungen bekommen, aber keinen Einsatz durchgeführt.
Der Generalbundesanwalt hat acht Trojaner-Einsätze durchgeführt.
Die Justizstatistik schlüsselt leider nicht auf, bei welchen Straftaten der kleine Staatstrojaner eingesetzt wird. Das Bundesjustizamt sagt, dass „vor allem“ Drogendelikte Anlass für Überwachung sind.
15 große Trojaner
Mit der „Online-Durchsuchung“ hacken Ermittler Geräte, um sämtliche Daten auszuleiten. Dieser „große Staatstrojaner“ wurde 32 Mal angeordnet. In 15 Fällen wurde der Einsatz „tatsächlich durchgeführt“. Das ist ein Allzeit-Rekord.
Der Generalbundesanwalt hat sechs Anordnungen in vier Verfahren bekommen. Anlass waren laut Statistik vier Mal kriminelle oder terroristische Vereinigungen und drei Mal Hochverrat. In zwei Fällen hat der oberste Ermittler tatsächlich gehackt.
Bayern hat fünf Mal gehackt, vier Mal wegen Drogen und einmal wegen Mord. Nordrhein-Westfalen hackte vier Mal, von zwölf Anordnungen ergingen zehn wegen Erpressung und zwei wegen Kriegswaffen. Hamburg hackte zweimal, wegen Straftaten gegen die sexuelle Selbstbestimmung. Baden-Württemberg hackte einmal, von sechs Anordnungen ergingen fünf wegen Erpressung und eine wegen Mord. Rheinland-Pfalz hackte einmal wegen Drogen.
Für und gegen Sicherheit
Politisch werden Staatstrojaner meist mit Terrorismus, Mord und Totschlag oder Straftaten gegen die sexuelle Selbstbestimmung begründet. Spitzenreiter sind jedoch auch weiterhin Drogendelikte. Damit verhindert der Staat, dass Sicherheitslücken geschlossen werden, um Drogen-Dealer zu bekämpfen.
Die Polizeibehörden haben mehrere Staatstrojaner, die sie einsetzen können. Das BKA hat selbst einen Trojaner mit dem Namen Remote Communication Interception Software programmiert. Ab 2013 hatte das BKA den Trojaner FinSpy von FinFisher. Seit 2019 nutzt das BKA auch Pegasus von NSO. Welche weiteren Trojaner Polizei und Geheimdienste haben, will keine Bundesregierung öffentlich sagen.
Mehr staatliches Hacken
Erst seit sechs Jahren gibt es offizielle Statistiken, wie oft die deutsche Polizei Staatstrojaner einsetzt. Seitdem steigen die Zahlen Jahr für Jahr.
In den vergangenen Jahren waren die veröffentlichten Zahlen oft falsch. Wir fanden Widersprüche, deshalb mussten Justizbehörden und Bundesjustizamt die Zahlen korrigieren. Ermittlungsbehörden hatten das Hacken von Geräten mit dem Abhören von Telefonaten verwechselt.
Die schwarz-rote Bundesregierung weitet das staatliche Hacken massiv aus. Die Bundespolizei soll Staatstrojaner gegen Personen einsetzen, die noch gar keine Straftat begangen haben. Bundeskriminalamt und Bundespolizei sollen bei Cyberangriffen zurück hacken. Die Geheimdienste sollen mehr Hacken und Schwachstellen geheim halten.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Entscheidung des ZDF, einen Auftritt des Rappers Danger Dan und des Pianisten Igor Levit aus dem Programm zu nehmen, schlägt hohe Wellen. In einem offenen Brief kritisieren mehrere Fernsehräte, dass der Sender damit die Chance vergeben habe, eine Debatte über den Umgang mit Rechtsextremismus anzustoßen.

Das ZDF hat Danger Dan und Igor Levit aus der Kabarettsendung „Die Anstalt“ ausgeladen, weil das Lied „Keine Angst“ als Aufruf zur Gewalt verstanden werden könne. Die Ausladung erfolgt gegen den Willen der Redaktion, die die Entscheidung in ihrer Sendung (ab etwa Minute 47:00) kritisch aufarbeitet.
In einem offenen Brief kritisieren mehrere Fernsehräte die Entscheidung des ZDF als mutlos. Sie bedauern, dass der Redaktion nicht das Vertrauen entgegengebracht wurde, den Liedtext kritisch einzuordnen.
Ich habe diesen Brief ebenfalls unterschrieben. Seit September 2025 vertrete ich im ZDF-Fernsehrat den Bereich „Internet“. Über meine Erfahrungen dort schreibe ich auf netzpolitik.org regelmäßig meine Kolumne „Neues aus dem Fernsehrat“.
Der offene Brief im Wortlaut:
Sehr geehrter Herr Intendant, lieber Herr Dr. Himmler,
wir schreiben Ihnen heute als Mitglieder des Fernsehrats, um unserer Besorgnis und auch Ärger über die Ausladung der Künstler Danger Dan und Igor Levit aus der Jubiläumssendung zur 100. Ausgabe der „Anstalt“ Ausdruck zu verleihen.
Sie haben uns persönlich sowie die Öffentlichkeit darüber informiert, dass die Geschäftsleitung des ZDF die Präsentation des Liedes „Keine Angst“ unterbunden hat, weil „der Text des Liedes als Anleitung zum politischen Extremismus verstanden werden kann, der Selbstjustiz propagiert und rechtswidrige Taten und Gewalt nicht ausschließt.“ Die Entscheidung fiel gegen den Willen der Redaktion der „Anstalt“.
Es ist die – im ZDF-Staatsvertrag und in den Programmrichtlinien definierte – Aufgabe des ZDF, durch seine Angebote zu einem vielfältigen und kontroversen öffentlichen Diskurs beizutragen und dabei insbesondere die Menschenwürde sowie den demokratischen und sozialen Rechtsstaat zu fördern. Zur Erfüllung dieser Aufgabe tragen Satiresendungen wie die „Anstalt“ wesentlich bei. Sie thematisieren politische Entwicklungen in zugespitzter Form, fördern kritisches Denken und tragen so zur öffentlichen Meinungsbildung bei.
Der erstarkende Rechtsextremismus ist eine besondere Gefahr für Demokratie und Rechtsstaatlichkeit in Deutschland. Danger Dan entwirft in „Keine Angst“ eine Anleitung für den Einsatz gegen die Bedrohung durch die extreme Rechte. Viele Menschen im Land, Medienschaffende, Jurist*innen, Wissenschaftler*innen, Aktivist*innen, Künstler*innen erleben täglich rechtsextreme Gewalt und Einschüchterung. Auch Berichte über mangelnden Schutz durch staatliche Strukturen sind kein Einzelfall. Diese Entwicklung dürfte sich zuspitzen und besondere Bedeutung erlangen, wenn Rechtsextreme in Deutschland in Verantwortung kommen.
Das ZDF hat hier die Gelegenheit verpasst, anders als nach der Vorstellung von „Das ist alles von der Kunstfreiheit gedeckt“ im ZDF Magazin Royale in 2021, eine Debatte über Rechtsextremismus in Deutschland und die vielfältigen Möglichkeiten seiner Bekämpfung anzustoßen. Auch „Keine Angst“ ist unserer Auffassung nach von der Kunst- und Meinungsfreiheit gedeckt. Die darüber hinausgehende Frage, ob ein – die Programmrichtlinien verletzender – Aufruf zur Gewalt vorliegt, kann sich nicht aus der isolierten Betrachtung einzelner Liedzeilen, sondern nur im Kontext der gesamten Sendung beantworten lassen. Die dafür relevante kritische Einordnung des Liedtexts, auch mit den Künstlern, wäre Aufgabe der Redaktion der „Anstalt“ gewesen. Diese Möglichkeit wurde ihr ohne Not genommen. Nicht zuletzt weil der Text laut der öffentlichen Berichterstattung dem Justitiariat bereits Wochen vor dem geplanten Auftritt bekannt war, hätte die Geschäftsleitung bereits deutlich früher an die „Anstalt“ herantreten und sich von einer ausreichenden inhaltlichen Auseinandersetzung überzeugen können.
Die Absage des Auftritts von Danger Dan und Igor Levit zeugt damit nicht nur von fehlendem Mut, sondern auch von fehlendem Vertrauen in die Redaktion der Sendung, sich angemessen mit dem Lied auseinanderzusetzen. Wir befürchten, dass dies auch abschreckende Auswirkungen auf andere Formate haben kann. Auch aufgrund des konkreten Verfahrens und der Kurzfristigkeit der Absage entsteht zudem der öffentliche Eindruck, dass diese notwendige Debatte unterbunden werden soll. Wir halten die Absage daher für einen Fehler.
Mit freundlichen Grüßen
Cornelia Berger
Mitglied im Fernsehrat als Vertreterin von ver.di – Vereinte DienstleistungsgewerkschaftMaike Finnern
Mitglied im Fernsehrat als Vertreterin des Deutschen GewerkschaftsbundesDilan Deniz Kılıç
Mitglied im Fernsehrat als Vertreterin des Bereichs „Muslime“Lisa Paus
Mitglied im Fernsehrat als Vertreterin des BundesAngela Spizig
Mitglied im Fernsehrat als Vertreterin aus dem Bereich „Medienwirtschaft und Film“ aus dem Land Nordrhein-WestfalenGabriela Terhorst
Mitglied im Fernsehrat als Vertreterin des Bundes für Umwelt und Naturschutz Deutschland e. V.Erik Tuchtfeld
Mitglied im Fernsehrat als Vertreter des Bereichs „Internet“Jörn Voß
Mitglied im Fernsehrat als Vertreter des Bereichs „Bürgerschaftliches Engagement“
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Der Einsatz sogenannter künstlicher Intelligenz im Kreativbereich ist schambehaftet und wird in der Regel argwöhnisch beäugt. Dabei zählt am Ende die Qualität eines Werkes – und die müssen wir erst einmal erkennen.

Kaum jemand entkommt den Heilsversprechen oder auch apokalyptischen Prophezeiungen rund um sogenannte künstliche Intelligenz. Sie gilt wahlweise als Booster für Wirtschaft und Forschung oder als Killer für Klima und Kultur. Bislang bewegt sie vor allem die Portfolios von Aktienanlegern.
Als jüngst ein betagter Journalist ganze Texte mit einer KI generieren ließ, war die Empörung groß. Sofort mahnten besorgte Kollegen: Die KI nehme uns das Denken ab. Denken sei aber gesund. Ergo verdumme uns die KI – wir sterben früher! Teilnehmer eines Workshops für kreatives Schreiben beichteten, dass sie heimlich KI für eine Schreibaufgabe nutzten. „Manche gestanden es tränenreich und sogar voller Selbstekel“, heißt es. Andere Medienmacher ergriffen die Gelegenheit beim Schopfe, um sich und ihre Arbeit heiligzusprechen: Das eigene Unternehmen solle „ein Fest für Menschen von Menschen“ bleiben.
Auch im künstlerisch-kreativen Bekanntenkreis rümpft man standardmäßig die Nase, wenn es um das Thema KI geht. Auf Nachfrage stellt sich aber doch heraus, dass die meisten in der einen oder anderen Form mit Chatbots arbeiten. Die Musikerin holt sich Inspiration für ihre Songs, der Autor für seine Texte. Und für Verwaltungsaufgaben geht es oftmals gar nicht mehr ohne: Der Start-up-Gründer rechnet seine Excel-Tabellen „mit Chat“ durch. Und der befreundete Software-Entwickler nutzt täglich Claude.
Die Frage sollte deshalb längst nicht mehr „Warum KI?“, sondern „Wie KI?“ lauten. Denn am Ende zählen doch bekanntermaßen Qualität und Aussagekraft eines Werkes sowie der ökonomische Nutzen für den Anwender.
Alles nur geklaut
In der Kulturkritik ist der größte Vorwurf an die KI ihre fehlende Originalität. Denn alles, was ein Chatbot produziert, sei ja nur geklaut. Das stimmt gewissermaßen. Aber genau genommen gab es Billigware, Ideenklau, Propaganda und Schwindeleien auch schon lange zuvor, mit und ohne Computerunterstützung.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
So ist die meistverkaufte 12-Inch-Single aller Zeiten und einer der prägendsten Songs der 80er auch „geklaut“: „Blue Monday“ von New Order. Die Band hatte das Lied aus vielen kleinen Soundschnipseln anderer Musiker zusammengebaut, wie der YouTuber „Creating Music and Sound“ in einem Video hervorragend erklärt. New Order nutzte dafür sogar ein Sample von Kraftwerk.
Auch der deutsche Produzent Moses Pelham hat Kraftwerk gesampelt. Pelham schnitt zwei Sekunden aus Kraftwerks „Metall auf Metall“ und legte sie als Dauerschleife unter „Nur mir“, produziert für die Rapperin Sabrina Setlur. Kraftwerk klagte. Seit 1999 streiten die Kontrahenten vor Gericht. Abseits einer rechtlichen Beurteilung zeigt die unterschiedliche Verwendung der beiden Kraftwerk-Stücke, dass es auf die Idee hinter dem Sampling ankommt.
Mehr als die Summe aller Teile
Pelhams Sampling erfüllt keine wirkliche Funktion, in „Nur mir“ erscheint es wahllos und austauschbar. Anders ist das bei New Order und „Blue Monday“. Die vielen verschiedenen, genial zusammengesetzten Elemente werden in der Summe zu einer mächtigen „Wall of Sound“. Durch die besondere Idee und das handwerklich ausgezeichnete Arrangement entsteht ein gänzlich neues Werk, das über seine Einzelteile hinauswächst und bis heute fasziniert.
Eine KI schafft es dagegen nicht, eigenständig über die Summe der verfügbaren Daten hinauszugehen. Für diesen letzten und essenziellen Schritt braucht es den ideenreichen Anwender. Gerade deshalb sind Wertschätzung für Qualität und der Blick auf den Kontext von Inhalten in einer von Massenproduktion bestimmten Zeit so wichtig.
Die Entwicklung von Geschmack und Medienkompetenz wird damit zum wichtigen Mittel im kulturellen und politischen Umgang mit einer zunehmend vermüllten Welt. Zugegeben eine äußerst schwierige Aufgabe in Zeiten der Dauerablenkung. Dabei sind die qualitativen Unterschiede von KI-Content gewaltig.
Der entscheidende Unterschied
Einerseits begeistern viele Content Creator wie „Gossipgoblin“ oder „Demonflyingfox“ sowie der Künstler Jon Rafman rasant wachsende Fan-Gemeinden mit durchdachten und unterhaltsamen KI-Inhalten. Andererseits fluten banale Aktivisten, Propagandisten und Meme-Macher das Netz mit KI-generiertem Schund. Zu den unzähligen Negativbeispielen gehören menschenverachtende Videos von Donald Trump und die „Musik“ des rechtsradikalen KI-Avatars Danny Bones, dessen Macher die erfundene Figur als Dreckschleuder für ihre politischen Parolen benutzen.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Ob politische Hetzer oder feinsinnige Künstler – sie alle nutzen dabei dieselben Werkzeuge. Hinter den einen Inhalten stecken betrügerische Geschäftsinteressen und hinterhältige Propaganda, hinter den anderen der Wille, Mitmenschen nachhaltig zu bewegen und zu inspirieren. Die Werte von Produzenten und Konsumenten machen schließlich den entscheidenden Unterschied.
Handarbeit bleibt Handarbeit
Vor knapp einhundert Jahren verteilten der Deutsche Musiker-Verband und die Internationale Artisten-Loge ein Flugblatt gegen den Tonfilm. „Tonfilm ist Kitsch“, stand in dicken schwarzen Buchstaben darauf. „100% Tonfilm = 100% Verflachung.“ Die neue Technik sei „wirtschaftlicher und geistiger Mord“. Wer Kunst und Künstler liebe, lehne den Tonfilm ab. Hinter dem Flugblatt standen die Kinomusiker – sie begleiteten damals Stummfilme live im Saal. Durch den Tonfilm verloren sie ihre Arbeit und das Kino seinen ursprünglichen Charakter.
Die Kritik am Tonfilm scheint heutzutage seltsam abstrakt, auch wenn seitdem tatsächlich eine gewisse Verflachung des Kinos eintrat und das Aussterben der Live-Musiker in den Sälen tragisch ist. Der Fortschritt durch neue Technologien hat immer einen hohen Preis. Dennoch entsteht neben der Massenware der zeitgenössischen Unterhaltungsindustrie bis heute sehr viel Schönes auf den Bildschirmen.
Die KI nimmt uns geradezu in die Pflicht, unsere Sinne zu schärfen und ganz genau hinzusehen, um am Ende die Qualität eines Werkes besser wertschätzen zu können. Gute Handarbeit, auch mit Unterstützung einer Maschine, bleibt gute Handarbeit.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die 29. Kalenderwoche geht zu Ende. Wir haben 14 neue Texte mit insgesamt 117.150 Zeichen veröffentlicht. Willkommen zum netzpolitischen Wochenrückblick.
Liebe Leser:innen,
mein Kollege Timur hat diese Woche einen umfangreichen Text über das neue Kompetenzzentrum der Bundesagentur für Arbeit veröffentlicht. Das soll „organisierten Leistungsmissbrauch“ aufdecken. Und je weiter ich beim Lesen kam, desto mehr schüttelte ich den Kopf. Am Ende blieb ein Gefühl: Hier wird medienwirksam einem angeblich großen Problem der Kampf angesagt. Aber ob dieses große Problem überhaupt existiert, ist nicht klar. Die wenigen verfügbaren Zahlen, die es zu „bandenmäßigem Leistungsmissbrauch“ gibt und die Timur darlegt, sprechen eher eine andere Sprache.
Eine klare Sprache sprechen jedoch diejenigen, die sich darum sorgen, dass all das mehr Misstrauen gegen Arbeitssuchende aus dem Ausland schürt. Dass rassistisch diskriminierte Menschen noch mehr Probleme bei ihren Anträgen bekommen, wenn eine Auswertung Stereotype reproduziert und so Menschen, die diesen Stereotypen entsprechend, ungleich öfter besonderen Kontrollen unterzogen werden.
Die Innenministerkonferenz im Juni hat klargemacht, was die Zielrichtung ist. Sie will mehr Datenaustausch und KI-Analysen mit dem Ziel „einer datenbasierten Risikoanalyse im Sinne einer Verdachtsgenese“. Was die Innenminister:innen auch wollen: Menschen aus anderen EU-Ländern sollen es schwerer haben, überhaupt an Sozialleistungen zu kommen, wenn sie in Deutschland sind. Das treibt systematisch Ausgrenzung und Abschottung voran. Die Freizügigkeit, eine der großen Errungenschaften der EU, wird so in ihrer Idee ausgehöhlt bis zur Unkenntlichkeit.
Gleichzeitig säen die ständigen Erzählungen von Sozialbetrüger:innen aus anderen Ländern und der Fokus auf „Verdachtsmomente“ ein Misstrauen in der Gesellschaft, das großen Schaden anrichtet. Wo jemand kontrolliert wird, muss doch auch etwas dran sein, oder? So etabliert sich eine Kultur, die Maßnahme für Maßnahme, Kompetenzzentrum für Kompetenzzentrum den Zusammenhalt vergiftet.
Doch Zusammenhalt bräuchten wir doch jetzt umso mehr, genau wie soziale Sicherheit für all jene, die Unterstützung brauchen. Maschinen, deren Aufgabe es ist, Verdächtigungen zu generieren, lösen diese Herausforderungen mit Sicherheit nicht.
Viele Grüße
anna
Degitalisierung: Look behind you
Die letzten Wochen waren voller dreiköpfiger Affen, mit denen die tollpatschig bis fintenreich agierende Bundesregierung von ihren Gesetzesvorhaben ablenken will. Was will sie aber damit eigentlich erreichen? Von Bianca Kastl –
Artikel lesen
Verbot für unter 13-Jährige: Von der Leyen will Alterskontrollen weit über Social Media hinaus
Die EU-Kommissionspräsidentin will das australische Modell drastisch ausweiten und plant flächendeckende Alterskontrollen im Netz. Treffen kann es nicht nur soziale Medien, sondern auch App-Marktplätze, Videospiele, Chatbots. Grundlage sind neue Empfehlungen eines Expert*innen-Gremiums. Von Sebastian Meineck –
Artikel lesen
Sicherheitsgesetz-Welle: Einer Demokratie unwürdig
Am Freitag hat der Bundestag den Einsatz von KI-Kameras an Bahnhöfen beschlossen. Weitere automatisierte Überwachungstools sollen folgen. Doch die haben in einer Demokratie nichts verloren. Ein Kommentar. Von Martin Schwarzbeck –
Artikel lesen
Gegenwind für Bundesregierung: Mehr als eine halbe Million Menschen wollen Informationsfreiheit retten
Damit hat Schwarz-Rot offenbar nicht gerechnet: Heftige Kritik am Angriff auf die staatliche Transparenz kommt nicht nur von der Opposition, sondern aus der Koalition selbst. Dazu erreicht eine Petition gegen das Vorhaben bemerkenswerten Zulauf. Von Markus Reuter –
Artikel lesen
Videoüberwachung in Berlin: Adesso SE baut Verhaltensscanner für die Polizei
Die Videoüberwachung mit automatisierter Verhaltenserkennung, die in Berlin geplant ist, wird von Adesso SE errichtet. Damit baut erstmals in Deutschland ein privatwirtschaftliches Unternehmen eine derartige Infrastruktur in den öffentlichen Raum. Adesso SE ist für ein massives Datenleck bekannt. Von Martin Schwarzbeck –
Artikel lesen
Daten-Skandal: Schufa speichert alte Datensätze über Millionen von Menschen
Als junger Mensch mal pleite gewesen, aber heute finanziell alles okay? Der Schufa ist das offenbar egal, sie berechnet Scores aus historischen Daten – Kunden können die offiziell für Tests nutzen. NDR und SZ haben einen weiteren Datenskandal der Schufa aufgedeckt. Von Markus Reuter –
Artikel lesen
Reformpaket: Schwarz-Rot will 99 Prozent der deutschen Unternehmen vom Datenschutz ausnehmen
Die schwarz-rote Koalition will nicht nur bei der Informationsfreiheit, sondern auch beim Datenschutz die Axt anlegen. Sie plant unter anderem pauschale Ausnahmen für kleine und mittelständische Unternehmen und will die Aufsicht zentralisieren. Kritik kommt von Datenschutzexpert:innen, Aufsichtsbehörden und Zivilgesellschaft. Von Ingo Dachwitz –
Artikel lesen
Geschichten aus dem DSC-Beirat : Der Sommer der Social-Media-Verbote
Die EU-Kommission will bald einen Gesetzentwurf für ein europäisches „Mindestalter“ vorlegen. Doch während die Frage nach dem „Ob“ von Alterskontrollen politisch entschieden scheint, ist die Frage nach dem grundrechtskompatiblen „Wie“ längst nicht beantwortet. Dabei gäbe es ganz andere Möglichkeiten, das Netz zu einem besseren Ort zu machen. Von Svea Windwehr –
Artikel lesen
Misstrauen gegen Arbeitssuchende: Das Schattenboxen mit dem „organisierten Leistungsmissbrauch“
Mit einem neuen Kompetenzzentrum will die Bundesagentur für Arbeit effizienter „organisierten Leistungsmissbrauch“ aufdecken. Fachleute zweifeln, ob das Problem existiert, und befürchten: Insbesondere rassistisch diskriminierte Menschen könnten so ins Visier geraten und nicht die Leistungen bekommen, die ihnen zustehen. Von Timur Vorkul –
Artikel lesen
Aufrüstung der Geheimdienste: Innenministerium lässt Datenkäufe in der Grauzone
Die Bundesregierung verrät nicht, ob deutsche Geheimdienste bei Databrokern Daten aus der Werbeindustrie kaufen. Vieles spricht dafür, doch auch die neue Geheimdienst-Reform soll keine klare Rechtsgrundlage schaffen. Kritiker:innen wie die Bundesdatenschutzbeauftragte haben verfassungsrechtliche Bedenken. Von Ingo Dachwitz –
Artikel lesen
Transparenzbericht 2. Quartal 2026: Unsere Einnahmen und Ausgaben – und Gewitterfronten
Unwetter kommen mal aus heiterem Himmel, mal kündigen sie sich lange vorher an. In beiden Fällen hilft es, gut gewappnet zu sein. Dank eures Rückenwindes sind wir das. Von netzpolitik.org –
Artikel lesen
„Schutz kritischer Infrastruktur“: Auch Brandenburg will Informationszugang einschränken
Berlin und Bund legen vor, Brandenburg zieht nach. Auch hier plant die Regierung, Informationsfreiheitsrechte zu schwächen. Wieder sollen Sicherheitsbedenken die Intransparenz rechtfertigen. Von Rika Baack –
Artikel lesen
Bericht mit Mängeln: Wissenschaftlicher Anstrich für Alterskontrollen
Im Namen des Jugendschutzes sollen alle im Netz ihr Alter nachweisen, das will EU-Kommissionspräsidentin Ursula von der Leyen (CDU). Die Forderung stützt sie auf einen Expert*innen-Bericht, der bei Alterskontrollen erhebliche Mängel aufweist. Die Analyse. Von Sebastian Meineck –
Artikel lesen
Meinungsfreiheit: Wie wir Hass bekämpfen, ohne die Freiheit des Wortes zu verlieren
Das Grundgesetz gewährt Meinungsfreiheit, auch für beunruhigende Meinungen. Die Geistesfreiheit ist inhaltlich unbeschränkt und gerichtlich durchsetzbar. Doch Meinungsstreit schützt nicht vor Widerspruch, Protest und Empörung. Wir brauchen klare Regeln gegen Hass und Hetze – gerade im Netz. Von Gastbeitrag, Johannes Masing –
Artikel lesen
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Das Grundgesetz gewährt Meinungsfreiheit, auch für beunruhigende Meinungen. Die Geistesfreiheit ist inhaltlich unbeschränkt und gerichtlich durchsetzbar. Doch Meinungsstreit schützt nicht vor Widerspruch, Protest und Empörung. Wir brauchen klare Regeln gegen Hass und Hetze – gerade im Netz.

Dürfen wir heute jede Meinung, jede politische Position öffentlich äußern? Dürfen wir auch für Ordnungsvorstellungen eintreten, die die Errungenschaften der Verfassungsrechtsprechung, die Grundrechte, die Gleichheit der Menschen wie letztlich die Meinungsfreiheit selbst infrage stellen?
Die verfassungsrechtliche Antwort ist ein klares: Ja.
Grundgesetz gewährt Meinungsfreiheit
Das Bundesverfassungsgericht formuliert das so: „Das Grundgesetz gewährt Meinungsfreiheit im Vertrauen auf die Kraft der freien öffentlichen Auseinandersetzung […] grundsätzlich auch den Feinden der Freiheit. Der parlamentarische Rat bekannte sich hierzu auch gegenüber dem soeben erst überwundenen Nationalsozialismus. […] Entsprechend gewährleistet Art. 5 Abs. 1 und 2 Grundgesetz die Meinungsfreiheit als Geistesfreiheit unabhängig von der inhaltlichen Bewertung ihrer Richtigkeit, rechtlichen Durchsetzbarkeit oder Gefährlichkeit“.
Wir dürfen also auch die Grundlagen unserer liberal-individualistischen Ordnung selbst infrage stellen – bis hin zu Forderungen nach einem Kalifat, einem fundamentalistisch-christlichen Staat, autoritären Führern oder einen libertären Staat des Stärkeren. Wir dürfen Forderungen erheben, die nach der Ewigkeitsgarantie des Grundgesetzes nie durchgesetzt werden dürften. Das Grundgesetz setzt darauf, dass sich der Geist der Freiheit in Freiheit behauptet.
Inhaltliche Grenzen gibt es im Privatrechtsverhältnis zwischen Bürgern, wo die Grundrechte nicht unmittelbar gelten: Über meine Nachbarn kann ich nicht beliebig herziehen, da kann ich auch nicht alles sagen, was ich denke. Im Übrigen aber gibt es Grenzen nur für das „Wie“ der Meinungsverbreitung. Das Grundgesetz ermächtigt erst dann zum Eingriff, „wenn Meinungsäußerungen die rein geistige Sphäre des Für-richtig-Haltens verlassen und in Rechtsgutverletzungen oder erkennbar in Gefährdungslagen umschlagen.“
Die maßgebliche Grenze bildet die Friedlichkeit. Der Gesetzgeber darf vor Äußerungen schützen, die „ihrem Inhalt nach erkennbar auf rechtsgutgefährdende Handlungen hin angelegt sind, d. h. den Übergang zu Aggression oder Rechtsbruch markieren“. (Dies ist auch die Interpretationsanleitung für die Strafnormen von Hass und Hetze oder die Befürwortung von Gewalt.)
Meinungsfreiheit unter Druck
Diese Meinungsfreiheit gerät unter Druck. In einer zunehmend polarisierten Gesellschaft und umso mehr, wenn Kriege in sie hineinwachsen, werden Gegenpositionen leicht als feindliche Einschüchterung, Rechtsgutverletzung oder Aggression empfunden.
Umgekehrt schlagen in einer solchen Situation Meinungsäußerungen auch tatsächlich schneller in Einschüchterung und bedrohliche Feindseligkeit um. Hier die Linie zu finden, ist nicht einfach.
Dabei macht es mir durchaus Sorge, wenn der Europarat ein förmliches Anschreiben an den deutschen Innenminister richtet, um seiner Sorge um die Meinungs- und Demonstrationsfreiheit in Deutschland Ausdruck zu geben – auch wenn das Schreiben nicht in jedem Punkt überzeugt.
Das Bundesverfassungsgericht stellt jedenfalls in einem freiheitlichen Sinne klar, dass allein der Schutz vor Beunruhigung durch Konfrontation mit provokanten Meinungen keine Einschränkung der Meinungsfreiheit erlaubt. „Die mögliche Konfrontation mit beunruhigenden Meinungen, auch wenn sie in ihrer gedanklichen Konsequenz gefährlich und selbst wenn sie auf eine prinzipielle Umwälzung der geltenden Ordnung gerichtet sind, gehört zum freiheitlichen Staat. Der Schutz vor einer Beeinträchtigung des ‚allgemeinen Friedensgefühls’ oder der ‚Vergiftung des geistigen Klimas’ sind ebenso wenig ein Eingriffsgrund wie der Schutz der Bevölkerung vor einer Kränkung ihres Rechtsbewusstseins durch totalitäre Ideologien.“
Hierin liegt eine Zumutung ‑ und zugleich ein großes Zutrauen in die Meinungsfreiheit.
Menschenbild des Grundgesetzes
Allerdings ist dieses Zutrauen in der neuen Rechtsprechung zu den Parteiverboten und zum Ausschluss der Parteienfinanzierung ein Stück weit verloren gegangen. Hier wird nicht mehr wie früher maßgeblich auf eine „aktiv kämpferische, aggressive Haltung“ abgestellt, sondern unmittelbar darauf, ob die Programmatik einer Partei inhaltlich mit dem Kernbereich der Verfassung vereinbar ist.
Unabhängig von der Art der Propagierung ihrer Ziele wird materiell geprüft, ob etwa die Vorstellungen zum Staatsangehörigkeitsrecht oder zum Umgang mit Religion einer Partei mit der Menschenwürde und, abstrakter, dem „Menschenbild des Grundgesetzes“ vereinbar sind – oder andernfalls zu Sanktionen berechtigen.
Konsequenterweise findet dies dann seine Fortsetzung in den Berichten der Verfassungsschutzämter, und nicht anders dann in den sie kontrollierenden verwaltungsgerichtlichen Entscheidungen.
Man kann fragen, ob es richtig ist, der wehrhaften Demokratie ein so weites, primär wertebezogen-inhaltlich definiertes Verständnis zu unterlegen. Die Gefahr, hier auf eine abschüssige Bahn zu geraten, ist groß. Für Parteien nimmt dies die Meinungsfreiheit jedenfalls zurück – und zwar schon inhaltlich.
Inhaltlich unbeschränkte Geistesfreiheit
Es bleibt aber zu betonen, dass dies eine Ausnahme für die Parteien ist. Eine solche inhaltliche Beschränkung der Meinungsfreiheit gilt nur für politisch aktive Parteien, insbesondere für solche mit politischem Potential, und kann auch nur im Rahmen des aufwendigen Verfahrens vor dem Bundesverfassungsgericht sanktioniert werden.
Den Bürgerinnen und Bürgern als Individuen werden solche inhaltlichen Grenzen des Denkens nicht vorgegeben. Das gilt auch dann, wenn sie sich mit anderen zusammenschließen.
Für andere Vereinigungen als politische Parteien bleibt es auch nach neuerer Rechtsprechung dabei, dass Maßnahmen erst dann ergriffen werden können, wenn die Ziele kämpferisch-aggressiv verfolgt werden. Hier hält das Bundesverfassungsgericht ausdrücklich daran fest, dass die wehrhafte Demokratie die Meinungsfreiheit als inhaltlich unbeschränkte Geistesfreiheit für Vereinigungen nicht zurück nimmt. Die Offenheit der Meinungsfreiheit ist auch Vereinigungen verbürgt.
Verfassungstreue im öffentlichen Dienst
Noch nicht ganz ausgelotet sind die Grenzen der Meinungsfreiheit, die sich aus der Pflicht zur Verfassungstreue im öffentlichen Dienst ergeben.
Die letzten Jahrzehnte bestand weitestgehend Einigkeit, dass die alte Praxis des Radikalenerlasses mit der Regelanfrage zur Verfassungstreue bei den Verfassungsschutzämtern zutiefst illiberal und einer freiheitlich Ordnung nicht würdig war. Anfragen wurden deshalb nach 1990 in der Praxis nur noch aus konkretem Anlass in Ausnahmefällen gestellt – freilich mit erheblichen Unterschieden in den Ländern. Dies ist heute jedoch wieder unsicher geworden.
Bemerkenswert ist jedenfalls, dass sich die Gesetzeslage hierzu kaum geändert hat und weiterhin viel Raum für eine Kontrolle der politischen Überzeugungen von Beamtenanwärtern lässt; inzwischen kommt auch die Regelanfrage zurück.
Fraglich ist im Zuge der neueren Rechtsprechung allerdings, unter welchen verfassungsrechtlichen Bedingungen entsprechende Erkenntnisse von den Verfassungsschutzämter übermittelt werden dürfen. Die derzeitige Gesetzeslage erlaubt dies aber praktisch uneingeschränkt.
Es ist sicher richtig und durch die Verfassung vorgezeichnet, dass Beamte für die freiheitliche, demokratische Grundordnung jedenfalls funktionsabhängig einstehen müssen und insoweit Einschränkungen ihrer Meinungsfreiheit unterliegen.
Deutschland hat hier aber noch kein klares Maß gefunden, wieweit solche Pflichten reichen – und geht insoweit jedenfalls weiter als andere europäische Länder.
Meinungsstreit und Kampf um Tabus
All dies ändert nichts daran, dass die Meinungsfreiheit im allgemeinen Staat-Bürger-Verhältnis inhaltlich strikt gilt. Sie ist dabei auch gerichtlich durchsetzbar.
Dennoch fordert der Umgang mit ihr Mut. Denn selbstverständlich schützt Meinungsstreit nicht vor Widerspruch, vor Protesten und vor Empörung aus der Gesellschaft. Der Kampf nicht nur um das, was richtig ist, sondern auch um das, was zu sagen akzeptabel oder inakzeptabel ist, ist Teil der Meinungsfreiheit.
Meinungskampf ist immer auch Kampf um Tabus. Das liberale Skript vertraut darauf, dass erstarrten Tabus dann auch immer wieder entgegengetreten wird – nicht mit Ressentiments und Hetze, sondern mit der Kraft des Arguments.
Es ist die große Aufgabe des Rechts und der Gerichte dafür zu sorgen, dass dieses möglich ist und Tabus nicht durch soziale Macht erstickend wirken oder sogar zu Recht werden und erstarren. Den Gerichten ist hier eine große Verantwortung aufgetragen.
Unsere Gerichte leisten hier, insgesamt betrachtet, gute Arbeit. Erwähnt sei nur die Entscheidung des Bundesverwaltungsgerichts, mit der die Folgen der Bundestagsresolution zur BDS-Kampagne eingeschränkt wurden oder die zahlreichen Entscheidungen der Verwaltungsgerichte, mit denen Versammlungsverbote – etwa gegenüber fundamentalistisch-religiösen Vereinigungen, Verschwörungstheoretikern, Rechtsradikalen, pro-palästinensischen oder pro-russischen Gruppen aufgehoben wurden und werden.
Solche Entscheidungen sorgen dafür, dass Meinungsfreiheit nicht nur auf dem Papier steht, sondern Wirklichkeit ist.
Klare Regeln für Kommunikation
Mit der Meinungsfreiheit setzen wir letztlich immer auf das Argument – allem zum Trotz, und auch wenn man hieran heute manchmal verzweifeln möchte.
Eine Chance hat das Vertrauen in die Meinungsfreiheit nur dann, wenn es gelingt, klare Kommunikationsregeln zu installieren – Regeln, die nicht provokante Inhalte, aber manipulative Kommunikation, Hass und Hetze eindämmen. Unser zentrales Problem liegt dabei heute in der Eigenlogik der Netzkommunikation und ihrer Manipulationsanfälligkeit. Es wird alles darauf ankommen, dass solche Regeln auch im Netz Wirksamkeit entfalten.
Die Europäische Union setzt hierzu an. Insbesondere mit dem Digital‑Services‑ und dem Digital‑Markets‑Act hat sie eine anspruchsvolle Regulierung auf den Weg gebracht. Sie begibt sich damit auf einen steinigen Weg, der auch seinerseits aus der Perspektive der Meinungsfreiheit kritisch begleitet werden muss.
Dabei zeigt die Geschichte, dass faire Kommunikationsregeln immer nur sehr begrenzt gegenüber wirtschaftlicher Macht gesichert werden konnten. Wir müssen dies aber mit Macht angehen und die Europäische Union hierbei unterstützen – auch gegenüber den Interessen der USA und deren Unternehmen.
Wenn dieses wenigstens ansatzweise gelingt, dürfen wir weiter Zutrauen in die Meinungsfreiheit haben – auch das Zutrauen, dass sich die Kraft individueller Freiheit in Freiheit gegen deren Anfeindungen zu behaupten vermag.
Dass Freiheit freilich immer auch Risiko ist, gehört zu ihr selbst. Es definiert die Freiheit, dass wir ihr Ergebnis nicht voraussagen können.
Vielleicht ist dieses Risiko aber geringer als manch Sicherheitsversprechen.
Prof. Dr. Dr. h.c. Johannes Masing ist Rechtswissenschaftler und ehemaliger Richter des Bundesverfassungsgerichts. Dieser Text ist sein Keynote-Vortrag auf dem Berliner Kongress Wehrhafte Demokratie.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Im Namen des Jugendschutzes sollen alle im Netz ihr Alter nachweisen, das will EU-Kommissionspräsidentin Ursula von der Leyen (CDU). Die Forderung stützt sie auf einen Expert*innen-Bericht, der bei Alterskontrollen erhebliche Mängel aufweist. Die Analyse.

Am Montag hat sich EU-Kommissionspräsidentin Ursula von der Leyen (CDU) für umfassende Alterskontrollen im Netz ausgesprochen, die weit über soziale Medien hinausgehen. Die Pläne markieren das Ende der Arbeit eines EU-Gremiums für Kinder- und Jugendschutz im Netz. Nach fünf Monaten haben die beiden Co-Vorsitzenden die Ergebnisse vorgelegt.
Auf 156 Seiten schildern die Gesundheits-Expert*innen, warum unter anderem flächendeckende Alterskontrollen junge Menschen vor den Gefahren der digitalen Welt schützen sollen. Im Vorfeld hat das Duo in drei Terminen Fachleute angehört. Auf Grundlage des Berichts will die EU-Kommission nach dem Sommer ein Gesetz vorschlagen, so von der Leyen.
In aller Kürze haben wir den Bericht bereits am Montag zusammengefasst. Diese Analyse zeigt nun anhand von vier zentralen Problemen, warum der Bericht der Expert*innen auf tönernen Füßen steht. Der Fokus liegt dabei auf den Empfehlungen zu Alterskontrollen, weil sie auf besondere Weise Grundrechte einschränken.
Auf Anfrage von netzpolitik.org verteidigt der Co-Vorsitzende Jörg Fegert den Bericht als „wissenschaftsbasiert“. Er gibt an, dass die EU-Kommission ihn und seine Co-Vorsitzende Melchior „auch inhaltlich unterstützt“ habe. Maria Melchior verweist auf Anfrage auf ihren Kollegen.
- Überblick: Das empfiehlt der Bericht
- Erstes Problem: Hier spricht nicht „das Gremium“
- Zweites Problem: Irreführung bei Alterskontrollen
- Drittes Problem: Unklare Zielsetzung
- Viertes Problem: Unwissenschaftliche Sprache
Überblick: Das empfiehlt der Bericht
In der Debatte um Alterskontrollen und Social-Media-Verbote sind vor allem fünf Empfehlungen des Berichts zentral:
1. Drastische Ausweitung über soziale Medien hinaus: Social-Media-Verbot war gestern – die Expert*innen wollen praktisch alles mit einer Altersschranke versehen, was jungen Menschen schaden könnte. Das geht weit über das australische Modell hinaus. Treffen kann es laut Bericht neben sozialen Medien auch App-Marktplätze, Videospiele, Chatbots oder Videoplattformen. Den Rundumschlag bezeichnet der Bericht eher verharmlosend als „social media+“. Die EU-weite Altersgrenze soll bei 13 Jahren liegen.
2. Hohe Anforderungen an sichere Designs: Um für Jugendliche weiter zugänglich zu sein, müssten Plattformen wie TikTok und Instagram so manches ändern. Der Bericht warnt zum Beispiel vor suchtfördernden Mechanismen und manipulativen Designs, vor unendlichem Scrollen, Push-Benachrichtigungen und Personalisierung. Das EU-Gesetz über digitale Dienste (DSA) geht solche Risiken bereits an, gilt aber nicht für alle digitalen Räume. Hier könnte das geplante Gesetz über digitale Fairness (Digital Fairness Act) nachhelfen, heißt es im Bericht.
3. Beweistlastumkehr: Aktuell läuft es so, dass Aufsichtsbehörden einschreiten, wenn sie erfahren, dass ein Dienst im Netz gegen Regeln verstoßen könnte. Die Expert*innen wollen dieses Prinzip umkehren: Anbieter sollten zuerst beweisen, dass ihre Dienste für junge Menschen sicher sind, bevor sie überhaupt ohne Altersbeschränkung auf den europäischen Markt dürfen.
4. Strenge Alterskontrollen: Es soll „effektive“ Systeme zur Alterskontrolle für alle geben, heißt es im Bericht. Einfach ausgedrückt sollen die Kontrollen sicherstellen, dass junge Menschen keine unerwünschten digitalen Räume mehr betreten können.
5. Nationale Alleingänge plus EU-weite Regeln: Einerseits empfiehlt der Bericht EU-weite Regeln und warnt: „Die Fragmentierung des europäischen Binnenmarkts für digitale Dienstleistungen stellt ein reales Risiko dar.“ Andererseits heißt es: Mitgliedstaaten könnten dennoch eigene Wege gehen und etwa ein höheres Mindestalter als 13 Jahre festlegen. Zur Begründung verweist der Bericht lediglich auf „nationale und historische Kontexte“.
Erstes Problem: Hier spricht nicht „das Gremium“
Der Abschlussbericht der EU-Expert*innen ist nicht das erste Papier zu diesem Thema. Zuvor hatten sich auch ein deutsches Expert*innen-Gremium und der Deutsche Ethikrat geäußert. Es gibt aber einen wichtigen Unterschied.
Der Deutsche Ethikrat hat 26 Mitglieder; sie sollen laut Gesetz „naturwissenschaftliche, medizinische, theologische, philosophische, ethische, soziale, ökonomische und rechtliche Belange in besonderer Weise repräsentieren“ und ein „plurales Meinungsspektrum“ vertreten. Das deutsche Expert*innen-Gremium war mit 18 Mitgliedern auch interdisziplinär besetzt, mit Fachleuten für unter anderem Medienrecht, Medienpädagogik, Gesundheit oder Kriminologie.
Die Expertise hinter dem EU-Bericht dagegen ist schmaler. Verfasst haben ihn lediglich die beiden Co-Vorsitzenden des Gremiums, Jörg Fegert (Experte für Kinder- und Jugendpsychiatrie aus Ulm) und Maria Melchior (Expertin für öffentliche Gesundheit aus Paris). Sie schreiben: „Die Verantwortung für die Empfehlungen liegt allein bei uns.“
In einem Presse-Briefing der EU-Kommission wollten Journalist*innen wissen, wie die Empfehlungen des EU-Berichts zustande kamen. Die Antwort: Man habe im Gremium keinen Konsens angestrebt. Auf Anfrage von netzpolitik.org erklärt Fegert mehr dazu. Die Rolle von ihm und Melchior sei es gewesen, „wissenschaftsbasiert die Argumente abzuwägen und sich gemeinsam auf Empfehlungen zu einigen“. Der Prozess sei so angelegt gewesen, dass er auf „zeitnahe Ergebnisse“ abzielt. Man habe sich auf die „Erfahrung“ seiner Co-Vorsitzenden und von ihm „verlassen“.
Im Gegensatz zu den Empfehlungen des Deutschen Ethikrats und des deutschen Gremiums setzt der EU-Bericht also auf Vertrauen statt Debatte. Viele Nachrichtenmedien haben berichtet, das „EU-Gremium“ habe Empfehlungen vorgelegt. Aber das ist irreführend. In dem Abschlussbericht spricht kein Gremium, sondern ein Duo. Ein möglicher Grund für das Medienecho: Auch die EU-Kommission spricht in ihrer öffentlichen Kommunikation mal von den Co-Vorsitzenden des Panels, mal vereinfachend vom „Panel“.
Zweites Problem: Irreführung bei Alterskontrollen
Bei Alterskontrollen formulieren Fegert und Melchior Ansprüche, die nicht miteinander vereinbar sind. Einerseits sollen Alterskontrollen streng sein, wie aus ihrem Bericht hervorgeht. Sie sollen etwa das Alter von Personen „präzise“ feststellen und „robust“ sein gegen Umgehungsversuche.
Anderseits sollen Alterskontrollen dem Bericht zufolge mild sein: Sie sollen „verhältnismäßig“ sein, Grundrechte wahren und „höchsten“ Standards für Datenschutz und Privatsphäre entsprechen. Sie sollen „inklusiv“ sein und „diskriminierungsfrei“. Weiter sollen sie „auf die Verarbeitung von Ausweisdokumenten oder biometrischen Daten zum Zwecke der Altersschätzung verzichten“.
Der Knackpunkt: Strenge und milde Ansätze widersprechen sich. Wie wir bereits berichtet haben, gibt es keine Lösung, die Vorteile beider Ansätze in sich vereint. So brauchen präzise und robuste Alterskontrollen Belege, dass ein Mensch tatsächlich erwachsen ist. Sie brauchen Belege, dass jemand den Altersnachweis nicht von einer anderen Person geklaut hat. Möglich ist das aber nur mit Einbußen bei unter anderem Privatsphäre, Zugänglichkeit und Teilhabe. Wer alles auf einmal verspricht, führt in die Irre.
Die EU-Kommission hat eine App für Alterskontrollen entwickeln lassen, die „Mini-Wallet“. Hierfür sollen Menschen auch ihr Gesicht biometrisch scannen, wie ein Demo-Video zeigt. Damit soll die App prüfen, ob das Gesicht vor der Kamera mit dem Foto auf dem Ausweis übereinstimmt. Kurz nach Veröffentlichung des Prototypen hat ein IT-Sicherheitsexperte die App in nur zwei Minuten gehackt. Sowohl beim Deutschen Ethikrat als auch beim deutschen Expert*innen-Gremium ist die Mini-Wallet durchgefallen. Beide Gremien haben geschrieben, die Mini-Wallet sei „abzulehnen“.
Jörg Fegert, Co-Autor des EU-Berichts, war selbst Teil des deutschen Gremiums, das die Mini-Wallet ablehnt. Im EU-Bericht schreiben er und seine Co-Autorin jedoch das glatte Gegenteil: Die Mini-Wallet sei „robust, benutzerfreundlich und die Privatsphäre wahrend“, sie könne ein „geeignetes Werkzeug“ sein. Kritik an der Mini-Wallet kommt nicht zur Sprache.
Auf Anfrage von netzpolitik.org erklärt Fegert: „Es stimmt, dass ich auch Mitglied der deutschen Kommission war. Dort wurde über die Entscheidungen abgestimmt, es waren nicht alle Empfehlungen einstimmige Empfehlungen.“ Die Ablehnung der Mini-Wallet durch den Deutschen Ethikrat sei „eine Momentaufnahme in einer Pilotphase“ gewesen. Die Mini-Wallet sei noch nicht vollständig „zero-knowledge-proof“ gewesen.
Fegert nutzt die Bezeichnung „zero-knowledge-proof“ in seiner Antwort wie ein Adjektiv. Es ist aber ein Nomen. Das englische Wort „proof“ bedeutet hier nicht „geschützt“, sondern „Beweis“.
Auch im Bericht ist Zero Knowledge Proof ein wichtiges Stichwort. Hier schreibt das Duo, Methoden zur Alterskontrolle sollten diesen Standard nutzen. Einfach ausgedrückt soll er Tracking vermeiden: Nutzende sollen bei der Altersabfrage anonym bleiben. Dienste sollen bloß erfahren, ob jemand eine Altersschwelle überschreitet, mehr nicht. Das Problem: In den öffentlichen Spezifikationen zur Mini-Wallet ist dieser „Zero Knowledge Proof“ nach wie vor nur optional und nicht verpflichtend. Die von Fegert erwähnte „Momentaufnahme“ ist also immer noch Status quo.
Zuletzt gibt es eine praktische Hürde für die geplanten Alterskontrollen, wie aus dem Bericht hervorgeht. Viele junge Menschen haben keinen Ausweis, den sie in ihrer Alterskontroll-App hinterlegen könnten. EU-Mitgliedstaaten sollen dafür zuständige Stellen benennen, heißt es im Bericht: „Die Benennung vertrauenswürdiger Anbieter von Altersnachweisen (…) ist für das wirksame Funktionieren der Altersüberprüfung in der EU von entscheidender Bedeutung.“
Von wem sollen die Kinder und Jugendlichen in der EU ihre Altersnachweise bekommen? Das steht noch nicht fest. Es fehlt Klarheit, wie viel Bürokratie die Kontrollen im Alltag bedeuten – für Kinder, Familien und Behörden.
Drittes Problem: Unklare Zielsetzung
Es ist das wohl wichtigste Argument der Kritiker*innen von Alterskontrollen: Menschen können die Kontrollen einfach umgehen. Das liegt an der Architektur des Internets. Mit VPN-Diensten oder dem Tor-Browser lassen sich an einem Ort altersbeschränkte Websites ohne Schranken besuchen, und zwar kinderleicht. Der Internetverkehr fließt dann über Server an einem anderen Ort, etwa über ein anderes Land ohne Alterskontrollen.
In Australien, wo seit Dezember 2025 ein Social-Media-Verbot bis 16 Jahre gilt, umgeht sogar die Mehrheit junger Menschen die Altersschranken. Das zeigen mehrere erste Erhebungen. Auch Fegert und Melchior schreiben: „Erste Ergebnisse aus Ländern, die pauschale Altersbeschränkungen für den Zugang zu sozialen Medien eingeführt haben, zeigen, dass die meisten Minderjährigen einen Weg finden, diese Regelungen zu umgehen.“
Das weckt Zweifel, ob Alterskontrollen überhaupt geeignet sind, junge Menschen wirksam vor den Gefahren des Internets zu schützen. Für staatliches Handeln ist Geeignetheit ein zentraler Maßstab.
Diese Zweifel finden im Bericht keinen Platz. Stattdessen beschreiben Fegert und Melchior ein anderes Verständnis vom Zweck der Alterskontrollen. Sie verweisen auf die Minderheit der Betroffenen, die sich durch ein Social-Media-Verbot von digitalen Diensten zurückgezogen haben. Diese jungen Menschen würden dann mehr Zeit für Offline-Aktivitäten haben, zum Beispiel Sport. „Dies zeigt, dass ein fortschreitender Wandel hinsichtlich der Normen für die Nutzung von Social Media+ durch Minderjährige möglich ist und anerkannt werden muss“, schreibt das Duo.
Das ist zunächst Spekulation: Ob das Verbot wirklich gesellschaftliche Normen verändert hat, müssten Sozialwissenschaftler*innen untersuchen. Weiter spekuliert das Duo, Altersbeschränkungen würden „kulturellen Wandel fördern“. Und: „Die Wirksamkeit von Altersbeschränkungen würde einen Wandel in gesellschaftlichen Einstellungen erfordern.“
Damit beschreiben die beiden Gesundheits-Expert*innen einen fundamental anderen Ansatz. Demnach wären Alterskontrollen nicht etwa „robust“ gegen Umgehungsversuche, wie es an anderer Stelle im Bericht heißt. Sie wären kein Schutzschirm, der Gefahren von Kindern und Jugendlichen fernhält. Stattdessen wären Altersschranken vor allem ein Signal mit normativer Wirkung. Junge Menschen und Familien würden daraufhin ihren Umgang mit sozialen Medien überdenken, zur Einsicht gelangen und sich selbst schützen.
Was versprechen sich die Expert*innen also wirklich von Altersschranken: ein Signal oder einen echten Schutzschirm? Für Eltern dürfte der Unterschied wichtig sein. Sollten sie darauf vertrauen, dass Alterskontrollen ihre Kinder vor Gefahren abschirmen – oder müssten sie vielmehr bei ihren Kindern um Einsicht werben, weil die Kontrollen eher symbolisch sind?
Die Frage ist auch essentiell, um zu bewerten, ob Alterskontrollen rechtsstaatlich wären. Ein Signal ist ein sehr anderer Zweck als ein Schutzschirm. Der Erfolg lässt sich schwerer vorhersagen oder empirisch belegen. Aus rechtsstaatlicher Perspektive braucht es aber genaue Begründungen, ob Alterskontrollen geeignet und erforderlich wären, um ihren Zweck zu erfüllen.
Jörg Fegert kann auf Anfrage von netzpolitik.org „keine verfassungsrechtliche Problematik im deutschen Kontext erkennen“, schreibt er. Es gehe darum, nicht-altersangemessene Mechanismen und Inhalte von Kindern und Jugendlichen fernzuhalten. Zudem führt er einen weiteren, also dritten, Zweck von Alterskontrollen an. Demnach könnten Alterskontrollen zum „Empowerment“ junger Menschen beitragen, wenn Plattformen Beschwerden und Meldungen junger Menschen bevorzugt behandeln müssten. Einfach ausgedrückt: Alle sollen ihr Alter nachweisen – damit Inhaltsmoderator*innen bei TikTok oder Instagram Meldungen von Erwachsenen nachrangig behandeln.
Beide Erläuterungen des Experten blenden zentrale Aspekte aus: Altersschranken gelten für digitale Räume in der Breite, nicht allein für riskante Mechanismen und Inhalte. Davon betroffen wären nicht nur junge Leute, sondern alle 450 Millionen Menschen in der EU, die etwa ihre Ausweise und Gesichter scannen lassen müssten. Wer die Altersschranken nicht überwinden will oder kann, wäre von wichtigen Angeboten für Information und Teilhabe abgeschnitten. Das sind tiefe Eingriffe, die Grundrechte einschränken. Umso wichtiger ist die Frage nach dem genauen Zweck der Maßnahme und ihrer Verhältnismäßigkeit.
Bestenfalls bewertet das ein interdisziplinäres Gremium mit unter anderem Jurist*innen, die ihre Abwägungen und ihren Dissens öffentlich nachvollziehbar ausführen. Die EU-Kommission hat sich für einen anderen Weg entschieden.
Viertes Problem: Unwissenschaftliche Sprache
An mehreren Stellen nutzt der Bericht Formulierungen, die eher nach Pressestelle klingen als nach wissenschaftlicher Analyse. Mindestens drei Passagen fallen besonders ins Auge.
1. „state-of-the-art“: Das Duo schreibt, die Alterskontroll-App der EU (Mini-Wallet) entspreche dem „höchsten technologischen Standard“, („state-of-the-art“). Das ist auffällig wertend und beißt sich mit der Ablehnung von Ethikrat und deutschem Expert*innen-Gremium. Der Begriff steht auch in einer Pressemitteilung der EU-Kommission, die ihre eigene App als „state-of-the-art“ anpreist.
2. „Zugang zu Kindern“: Im Mai nutzte Ursula von der Leyen eine auffällige Formulierung: „Die Frage ist nicht, ob junge Menschen Zugang zu sozialen Medien haben sollten; die Frage ist, ob soziale Medien Zugang zu jungen Menschen haben sollten.“ Alltagssprache ist das nicht, sondern ein Stilmittel. Im Fokus steht nicht mehr, dass die die Politik jungen Menschen etwas wegnimmt. Stattdessen stehen Social-Media-Konzerne im Fokus, die Kindern anscheinend zu nahe kommen. Mehrfach übernehmen auch Fegert und Melchior das Stilmittel, etwa wenn sie darüber schreiben, wie Dienste „Zugang zu Kindern und Jugendlichen erhalten“.
3. „child safety gap“: Ein weiterer auffälliger Begriff im Bericht lässt sich nur mit Vorgeschichte verstehen. Anbieter wie Meta scannen anlasslos Nachrichten, um Hinweise auf sogenanntes Material von Kindesmissbrauch zu finden. Kritiker*innen haben dafür die Bezeichnung freiwillige Chatkontrolle etabliert. Rechtens ist diese Form der Massenüberwachung privater Kommunikation nur durch eine befristete Ausnahmeregelung. Eine Weile lang sah es so aus, als könnte sich die EU nicht auf eine Verlängerung einigen. Die Lobby-Organisation Thorn warnte deshalb vor einer „Kinderschutzlücke“ („child safety gap“). Der Begriff lenkt von der Kritik an der Maßnahme ab und rückt die Sicherheit von Kindern in den Fokus. Bislang fehlen stichhaltige Belege, ob Chatkontrolle wirklich zur Sicherheit beiträgt. Auch die EU-Kommission hat das Wort „gap“ in ihrer öffentlichen Kommunikation übernommen. In ihrem Bericht schreiben auch Fegert und Melchior vom „child safety gap“. Im Einklang mit der EU-Kommission fordern sie eine Verlängerung der freiwilligen Chatkontrolle und eine dauerhafte Chatkontrolle.
Das sind zunächst nur drei Details aus einem langen Papier. Aber sie werfen die Frage auf: Wie viel von diesem Bericht ist wissenschaftlich fundiert – und wie viel ist politische Agenda der EU-Kommission?
Fegert erklärt hierzu auf Anfrage von netzpolitik.org: „Wir waren in unseren Empfehlungen frei und unabhängig.“ Er bezeichnet den Bericht als „wissenschaftbasierte Politikberatung“. Im Zentrum stehe „Evidenz als Ausgangspunkt für die Entwicklung der Empfehlungen“. Er räumt jedoch ein: Expert*innen aus der EU-Kommission hätten ihn und Melchior „auch inhaltlich bei Recherchen und Informationsbeschaffung unterstützt“.
Was Kinder im Netz erleben, und was Politik daraus lernen kann
Bei mindestens zwei von drei Treffen des Expert*innen-Gremiums war Ursula von der Leyen persönlich vor Ort, wie auch Fegert bestätigt. Rund zwei Monate, bevor das Gremium seine Ergebnisse präsentiert hat, sagte von der Leyen: „Ohne Ergebnisse des Gremiums vorwegzunehmen: Es ist meine Überzeugung, dass wir einen zeitlichen Aufschub für soziale Medien in Betracht ziehen müssen.“ Damit hat die Kommissionspräsidentin ihren Expert*innen quasi in den Block diktiert, was sie von ihnen erwartet.
Bei der Präsentation des Papiers sagte von der Leyen schließlich: „Das sind genau die Belege, auf die wir gewartet haben.“ Fegert erklärt auf Anfrage: „Die Verantwortung für den Inhalt des Berichts und der Empfehlungen liegt ausschließlich bei uns Ko-Vorsitzenden.“
Wer wie das Duo einen Bericht von öffentlichem Interesse verfasst, dürfte Einflussnahme aus vielen Richtungen erleben – das allein muss nichts bedeuten. Entscheidend ist, was im Bericht steht, ob die Argumente vollständig und schlüssig sind. Und gerade beim grundrechtlich sensiblen Thema Alterskontrollen finden sich erhebliche Mängel. Losgelöst von den Beweggründen der Beteiligten erfüllt der Bericht damit eine bestimmte Funktion: Er gibt den netzpolitischen Plänen der EU-Kommission einen wissenschaftlichen Anstrich.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Berlin und Bund legen vor, Brandenburg zieht nach. Auch hier plant die Regierung, Informationsfreiheitsrechte zu schwächen. Wieder sollen Sicherheitsbedenken die Intransparenz rechtfertigen.

Die Brandenburger Landesregierung will das Akteneinsichts- und Informationszugangsgesetz (AIG) ändern. Gegenüber rbb|24 hat ein Sprecher des Innenministeriums am gestrigen Donnerstag bestätigt, dass sie aktuell an einem Gesetzentwurf arbeitet.
Wie schon der Berliner Senat begründet auch Brandenburg die Schritte mit einer abstrakten Gefahrenlage. „Der Schutz kritischer Infrastruktur ist angesichts verschiedenster Bedrohungslagen von entscheidender Bedeutung“, heißt es in der Mitteilung, die rbb|24 auf Anfrage erhielt. Die Änderungen sollen dem Land erlauben, besser auf solche Bedrohungen zu reagieren.
Das AIG regelt in Brandenburg bisher, wie Bürger*innen an behördliche Informationen gelangen. Es garantiert jeder Person ein Recht auf Akteneinsicht, solange nicht überwiegende öffentliche oder private Interessen dagegensprechen. Welche konkreten Änderungen das Land plant, ist noch offen. So tiefgreifend wie der Bund könne das Land aufgrund der Landesverfassung nicht vorgehen.
Die Schwächung der Informationsfreiheit liegt im Trend
Die Bundesregierung kündigte Anfang Juli in ihrem „Programm für Aufschwung und Beschäftigung“ an, dass sie das Informationsfreiheitsgesetz (IFG) massiv einschränken will. Zu den Vorhaben gehört, Informationen nur noch mit „berechtigtem Interesse“ herauszugeben und Organisationen, Unternehmen und Stiftungen das Recht völlig zu entziehen.
Brandenburg nimmt sich offenbar ein Vorbild an einem deutschlandweiten Trend. Weitere CDU- und SPD-geführte Bundesländer planen eine Beschneidung der Informationsfreiheitsrechte: Auch Schleswig-Holstein, Mecklenburg-Vorpommern und Thüringen legten mit Verweis auf Sicherheitsbedenken und Bürokratieabbau Gesetzentwürfe vor.
Berlin schaffte als erstes Bundesland Tatsachen: Das Abgeordnetenhaus zog den Anschlag auf das Berliner Stromnetz heran, um im März ein Gesetz zu verabschieden, mit dem Behörden Anfragen pauschal ablehnen können.
„Nicht mehr Sicherheit, sondern weniger Demokratie“
Fachleute kritisieren den Versuch, Intransparenz mit Sicherheitsbedenken rechtzufertigen. Die Jurist*innen Philipp Schönberger und Hannah Vos vom Transparenzportal FragDenStaat schreiben im Verfassungsblog: „Offensichtlich dient die diskursive Verknüpfung mit einer Bedrohungslage vor allem als Vehikel für eine möglichst weitreichende Abschirmung der Exekutive vor öffentlicher Kontrolle.“ Auch die Bundesbeauftragte für den Datenschutz und die Informationsfreiheit (BfDI) Prof. Dr. Louisa Specht-Riemenschneider warnte: „Wer Informationsfreiheit pauschal beschränkt, schafft nicht mehr Sicherheit, sondern weniger Demokratie.“
Für die Pläne der Bundesregierung hagelt es Kritik. Mehr als eine halbe Million Menschen wollen die Informationsfreiheit schützen, zeigt eine laufende Petition von FragDenStaat. Auch 131 Organisationen stellen sich gegen das Vorhaben. Selbst in den eigenen Reihen regt sich Widerstand: Die SPD-Bundestagsabgeordneten kündigten der Parteispitze in einem internen Papier an, sie würden nicht für die Abschaffung des bestehenden Transparenzniveaus stimmen.
Auch in Brandenburg dürfte es Gegenstimmen geben. Kurz vor den Neuigkeiten der Landesregierung warnte die Verbraucherzentrale Brandenburg vor der Entkernung des IFG. Sie verweist auf ein eigenes Verfahren gegen den Ostdeutschen Sparkassenverband – auf Akteneinsicht nach dem AIG.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Unwetter kommen mal aus heiterem Himmel, mal kündigen sie sich lange vorher an. In beiden Fällen hilft es, gut gewappnet zu sein. Dank eures Rückenwindes sind wir das.

{kind=link}
Wenn feuchtwarme Luft in kühlere Höhen aufsteigt, bilden sich Gewitterwolken. In Hitzephasen kann es einige Zeit dauern, bis sich die Anspannung entlädt. Zunächst liegt ein Knistern in der schwülen Luft, Windböen kommen auf, erste Blitze zucken. Donnergrollen, dann ein Wolkenbruch. Straßen werden geflutet, Menschen suchen hektisch Zuflucht unter Dachvorsprüngen und in Hauseingängen.
Im vergangenen Quartal gab es etliche solcher Unwetter. Hitzedom, Höllensommer, Wüstentage – die ursächliche Wetterlage hat viele Namen. Gleichzeitig kündigte sich auch im politischen Berlin ein nahendes Gewitter an.
Bereits Anfang Mai veränderte sich der Luftdruck über dem Regierungsviertel spürbar. Nach einem Jahr Schwarz-Rot zogen viele Bilanz: Die Koalition liefere nicht, zanke sich zu viel und verschleppe Reformen. Dunkle Wolken ballten sich über dem Reichstagsgebäude zusammen.
Kurz vor der Sommerpause und parallel zur Herrenfußball-WM donnerte es dann los: Ein Gesetzentwurf jagte den nächsten, im Eiltempo wurden Stellungnahmen von der Zivilgesellschaft verlangt, bevor das Kabinett dann seinerseits Entwürfe an den Bundestag übergab. Auch bei uns ging es mitunter hektisch zu. Der Teufel steckt bei Gesetzentwürfen im Detail. Und es braucht Zeit, um zu verstehen, welche Folgen geplante Maßnahmen haben.
Wir haben deshalb gerade viel auf dem Tisch: Biometrische Videoüberwachung, die Rückkehr der Vorratsdatenspeicherung, Fotofahndung im Netz, Reform der Nachrichtendienste – die Flut an gefährlichen Vorhaben ist schier endlos. Darüber hinaus will die schwarz-rote Koalition auch noch die Informationsfreiheit unterspülen.
So gehen wir nun in die Sommerpause und ins zweite Halbjahr. Doch die Ruhe ist trügerisch. Denn das Kabinett tagt auch in den kommenden Wochen und hinter den Kulissen werkelt die Regierung überfleißig an ihren Reformvorhaben. Es bleibt also drückend heiß und das nächste Gewitter zieht schon auf.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Die harten Zahlen
Dagegen ist die Wetterlage in unseren Finanzen erfreulich ruhig. Jedoch können unsere Spendeneinnahmen einen Tacken Rückenwind vertragen. Wir liegen zum Ende des ersten Halbjahres mit etwas über 6 Prozent hinter unseren Erwartungen.
Eine extra Brise eurer Unterstützung kann uns den nötigen Schwung für die solide Absicherung unseres Budgets verschaffen. Um die Redaktion von netzpolitik.org für politische Unwetterzeiten zu wappnen, ist eine regelmäßige – am besten monatliche – Unterstützung eine willkommene Rückendeckung.
Unsere Spendeneinnahmen
Im zweiten Quartal haben wir 186.900 Euro an Spenden von euch erhalten. Das ist ein gutes Ergebnis und liegt etwas mehr als 4 Prozent über unserem Plan. Weil das erste Quartal deutlich unter unseren Erwartungen blieb, schließen wir das erste Halbjahr bei den Spendeneinnahmen dennoch mit einem Minus in Höhe von 27.500 Euro ab.
Unsere Einnahmen
Insgesamt belaufen sich unsere Einnahmen im zweiten Quartal auf 193.872 Euro. Die Spendeneinnahmen betragen 96 Prozent der Gesamteinnahmen. Die restlichen 4 Prozent setzen sich aus regelmäßigen Einnahmen und den sonstigen Erlösen zusammen.
Regelmäßige Einnahmen erzielen wir durch Verkäufe im Webshop, der Verwertung unserer Veröffentlichungen im Pressespiegel und dem Zuschuss für den Platz im Rahmen des Freiwilligendienstes. In den sonstigen Erlösen stellen wir die Erstattungen für Ausfallzeiten aufgrund von Krankheit (AAG) und Zinserträge dar.
Unsere Ausgaben
Unsere Haushaltslage hat zugelassen, den Tarifabschluss im TVöD Bund mitzugehen und unser Einheitsgehalt (EG 13, Stufe 1) im Mai um 2,8 Prozent zu erhöhen. Verausgabt haben wir für Personalkosten im zweiten Quartal 225.377 Euro und liegen damit rund 9.500 Euro unter den veranschlagten Kosten laut unserem Stellenplan. Die Einsparung liegt unter anderem am Stellenwechsel in der IT. Dadurch war die Stelle der Systemadministration im April nicht besetzt.
Seit dem 1. Mai 2026 haben wir eine neue Leitung der IT: Daniel Tippmann folgte Christophe, der in den gut zwei Jahren zuvor erfolgreich die technische Infrastruktur von netzpolitik.org verschlankt und auf neuen Stand gebracht hat. Wir freuen uns auf die gemeinsamen Projekte mit Daniel!
In den Sachkosten haben wir für das zweite Quartal 61.163 Euro und damit rund 25.300 Euro weniger ausgegeben als kalkuliert. Das ist vor allem der monatlichen Kalkulation von Ausgaben geschuldet, die jedoch nicht monatlich, sondern punktuell im Jahr auftreten – wie Beratungs- und Fortbildungskosten.
Insgesamt haben wir im zweiten Quartal 2026 an Personal- und Sachkosten 286.540 Euro verausgabt.
Unser Projekt Reichweite hatten wir in den letzten beiden Quartalsberichten 2025 vorgestellt. Die Projektlaufzeit beträgt drei Jahre bis Herbst 2027. Die Finanzierung in Höhe von 200.000 Euro entnehmen wir aus unseren Rücklagen. In 2025 haben wir für das Projekt insgesamt 38.000 Euro vor allem für den Relaunch unserer Website und eine Stelle für die Verbreitung unserer Inhalte in den sozialen Medien ausgegeben. Im ersten Quartal 2026 haben wir lediglich Personalkosten in Höhe von etwas unter 7.600 Euro verausgabt.
Im zweiten Quartal konnten wir den Relaunch unserer Website abschließen und haben die Arbeit an der Installation sowie Konfiguration der neuen Software zur Verwaltung der Spendendaten aufgenommen. Dafür haben wir insgesamt 38.100 Euro aufgewendet. Im Projekttopf verbleiben somit etwas über 116.000 Euro, die bis Ende 2027 vor allem für Personalkosten im Bereich Social Media und Spendenverwaltung verplant sind.
Das vorläufige Ergebnis
Wir schließen das 2. Quartal mit einem Ergebnis in Höhe von ‑91.600 Euro ab. Laut Plan haben wir mit einem Ergebnis von ‑134.400 Euro gerechnet. Ein Minus in den ersten drei Quartalen beunruhigt uns nicht besonders, solange es im Rahmen unserer Erwartungen bleibt. Das gleichen wir nach unseren bisherigen Erfahrungen im vierten Quartal mit der Jahresendkampagne aus.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Danke für eure bisherige und zukünftige Unterstützung!
Wenn ihr uns unterstützen wollt, findet ihr hier alle Möglichkeiten. Am besten ist ein Dauerauftrag oder ein Lastschrifteneinzug. Hierfür fallen die geringsten Gebühren im Vergleich zu anderen Zahlungsarten an.
netzpolitik.org e.V.
IBAN: DE62430609671149278400
BIC: GENODEM1GLS
Zweck: Spende
Wir nehmen Spenden via Paypal an.
Wir sind glücklich, die besten Unterstützer:innen zu haben.
Unseren Transparenzbericht mit den Zahlen für das 1. Quartal 2026 findet ihr hier.
Vielen Dank an euch alle!
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Bundesregierung verrät nicht, ob deutsche Geheimdienste bei Databrokern Daten aus der Werbeindustrie kaufen. Vieles spricht dafür, doch auch die neue Geheimdienst-Reform soll keine klare Rechtsgrundlage schaffen. Kritiker:innen wie die Bundesdatenschutzbeauftragte haben verfassungsrechtliche Bedenken.

Das Haus von Innenminister Alexander Dobrindt (CSU) hat gerade einen Entwurf für eine tiefgreifende Geheimdienstreform vorgelegt. Das Bundesamt für Verfassungsschutz und der Bundesnachrichtendienst sollen weitreichende neue Befugnisse bekommen und auch technisch aufrüsten, etwa bei staatlichem Hacking, KI und Videoüberwachung.
Nach einer anderen Form der Überwachung sucht man im Gesetzestext jedoch vergeblich: Die Überwachung mit kommerziell gehandelten Daten. Insbesondere Daten, die angeblich nur für Werbezwecke gesammelt werden, sind inzwischen zur Handelsware geworden. Databroker haben beispielsweise metergenaue Standortdaten von Smartphones im Angebot. Auch Informationen zu Vorlieben von Personen oder ihrem Online-Verhalten lassen sich erwerben.
Der Fachbegriff für Überwachung auf Grundlage von Werbedaten ist ADINT. Der Begriff steht für Advertising-Based Intelligence, also werbebasierte Aufklärung, und taucht lediglich in der Begründung für das neue BND-Gesetz auf. Expert*innen sehen darin den Hinweis, dass deutsche Dienste durchaus ADINT nutzen könnten – allerdings ohne saubere Rechtsgrundlage.
Staatliche Überwachung mit kommerziellen Daten
Recherchen von netzpolitik.org und dem Bayerischen Rundfunk zeigen seit 2024, dass sich mit Standortdaten aus der Werbeindustrie auch hochrangige Beamte der Bundesregierung und der EU-Kommission, NATO-Militärstützpunkte und sogar Mitarbeitende von Geheimdiensten ausspionieren lassen.
Seit Längerem ist bekannt, dass US-Behörden wie das FBI oder die Abschiebe-Miliz ICE ADINT einsetzen. Zuletzt hatten Recherchen aufgedeckt, dass auch die ungarische und die österreichische Regierung Produkte eines ADINT-Dienstleisters erworben haben. Die Bundesregierung hatte Fragen von Journalist:innen dazu in der Vergangenheit nicht beantwortet.
Strittig ist, ob die Nutzung von ADINT-Daten durch deutsche Geheimdienste legal wäre. Ein Gutachten der Wissenschaftlichen Dienste des Bundestages weckte daran Zweifel. Auch die Bundesdatenschutzbeauftragte Louisa Specht-Riemenschneider und andere Expert:innen hatten wiederholt betont, dass es dafür eine ausdrückliche Grundlage im Gesetz brauche. Staatliche Stellen könnten sich nicht auf allgemeine Generalklauseln stützen, die es ihnen erlauben, Daten zu erheben.
Eingeständnis durch die Hintertür?
Eine klare Regelung für Datenkäufe konnte auch die Bundesbeauftragte für Datenschutz und Informationsfreiheit (BfDI) im neuen Gesetzentwurf nicht finden. Behördensprecher Karsten Füllhaase erklärt auf Anfrage von netzpolitik.org:
Der aktuelle Gesetzesentwurf enthält weder für das Bundesamt für Verfassungsschutz (BfV) noch für den Bundesnachrichtendienst (BND) eine explizite Rechtsgrundlage für den Ankauf und die Nutzung kommerzieller Daten, insbesondere von Werbedatenbanken. Die Bundesregierung stützt bereits nach der aktuell geltenden Rechtslage den Datenkauf auf die Generalklauseln nach § 8 Bundesverfassungsschutzgesetz bzw. § 5 BND-Gesetz. Diese Normen werden durch den vorgelegten Gesetzentwurf nur unwesentlich geändert.
Dennoch taucht das Wort „ADINT“ im Gesetzentwurf auf, und zwar in den Erläuterungen zu Paragraf 88 des neuen BND-Gesetzes. Dort geht es darum, unter welchen Bedingungen der deutsche Auslandsgeheimdienst Daten an andere Stellen weitergeben darf. Zitat: „Unter diese Norm fällt auch die Übermittlung von angekauften Datensammlungen z.B. von umfänglichen Werbedaten (sog. ADINT-Daten), oder von im Internet verfügbaren Datenleaks.“
Solche Daten können dem Entwurf zufolge auch automatisiert und in Gänze an andere übermittelt werden. Die Vermutung liegt nahe: Darf der BND solche Daten weitergeben, dann geht die Bundesregierung offenbar auch davon aus, dass er sie haben kann – und möglicherweise auch erwerben.
Auch an anderen Stellen taucht Ankauf von Daten in der Begründung des Gesetzes auf. „Damit wird deutlich, dass es sich um einen üblichen modus operandi des BND handelt“, schlussfolgert der Jurist Peter Schantz. Der ehemalige Ministerialdirektor im Bundesjustizministerium hat eine Stellungnahme zum Gesetzentwurf verfasst und kritisiert darin das Fehlen einer gesetzlichen Regelung. Für notwendig hält er sie unter anderem deshalb, weil Dienste auch sensible Daten kaufen könnten.
Bundesdatenschutzbeauftragte kritisiert Entwurf
„Hätte der Staat diese Daten auch selbst erheben dürfen?“ Diese Frage nach dem sogenannten “hypothetischen Ersatzeingriff“ müsse sich der Gesetzgeber stellen, so Schantz. Dabei müsse berücksichtigt werden, ob die Verkäufer die Daten selbst überhaupt rechtmäßig verarbeiten.
Im Fall von Werbedaten bezweifeln viele Fachleute – von Datenschutzbehörden über Jurist*innen bis hin zum Verbraucherschutzministerium –, dass deren Verarbeitung und Verkauf durch Databroker legal ist. Ursprünglich wurden die Daten in der Regel für Werbezwecke erhoben, nicht für Datenhandel oder Überwachung; die Einwilligung der Betroffenen kann allein deshalb nicht wirksam sein.
Auch die Bundesdatenschutzbeauftragte ist der Auffassung, „dass die Nutzung kommerzieller Werbedaten einer inhaltlich bestimmten und normenklaren gesetzlichen Ermächtigungsgrundlage bedarf“, erklärt deren Sprecher. Er weist auf das „potentiell sehr hohe Eingriffsgewicht“ der Überwachung mit Werbedaten hin. Das erfordere nach Auffassung der BfDI „verfassungsrechtlich neben erhöhten Anforderungen an Zweckbindung und Dokumentation auch ausreichende Kontrollmechanismen“. Schließlich würden die Maßnahmen heimlich erfolgen und betroffenen Menschen wäre eine nachträgliche Rechtsverfolgung kaum möglich. Der vorgelegte Gesetzentwurf erfülle diese Anforderungen nicht.
Ähnlich argumentiert Jurist Schantz: Kontrolle und Rechtsschutz müssten gewährleistet sein. Ihm zufolge müsse einbezogen werden, welcher Personenkreis betroffen ist, schließlich enthalten Pakete von Databrokern oft Daten über Millionen Menschen. Es drohe „die Umgehung der gesetzlichen und verfassungsrechtlichen Eingriffsvoraussetzungen, die an die staatliche Datenerhebung zu stellen wären“, warnt er.
In Großbritannien werden Datenkäufe kontrolliert
Politikwissenschaftler Thorsten Wetzling von der Stiftung Interface kritisiert den Gesetzentwurf mit Blick auf ADINT ebenso als unzureichend. Er und sein Co-Autor Corbinian Ruckerbauer gehörten zu den ersten, die in Deutschland den Blick auf die „Informationsbeschaffung mit der Kreditkarte“ gelenkt haben.
„Die Regierung pocht weiterhin auf größtmögliche Beinfreiheit bei ihren Datenkäufen“, kommentiert Wetzling heute. Andere Länder würden das anders handhaben. Ein Beispiel sei das Vereinigte Königreich, „wo zumindest ein Genehmigungsverfahren unter Beteiligung der unabhängigen Rechtskontrolle erforderlich wird, wenn ein Nachrichtendienst dort gekaufte Daten in seine eigenen IT-Systeme einverleiben will.“
In Deutschland hingegen sei bisher nicht geplant, dass der Unabhängige Kontrollrat auch bei der kommerziellen Datenbeschaffung tätig wird. Die Bundesbehörde soll bei der Kontrolle der Geheimdienste künftig grundsätzlich wichtiger werden – aber nicht im Bereich ADINT. Wetzling zufolge müsste der Kontrollrat eigentlich Verträge mit privaten Dienstleistern vor Kaufentscheidungen sichten dürfen oder die Nutzung gekaufter Daten in den Systemen des BND genehmigen.
Der Staat müsse nachrichtendienstliche Datenkäufe stärker begrenzen und wirksamer kontrollieren, sagt der Forscher. Dafür sprächen „gewichtige Argumente des Grundrechtsschutzes, aber auch der nationalen Sicherheit“, so Wetzling mit Blick auf das Gutachten der Wissenschaftlichen Dienste des Bundestages. Sie hätten hervorgehoben, dass „beim Ankauf von Daten aus Werbedatenbanken eine besondere Gefahr von Eingriffen in den Kernbereich der privaten Lebensgestaltung“ besteht und das „Erfordernis ausdrücklicher gesetzlicher Schutzvorkehrungen“ ins Spiel gebracht.
Keine harmlosen Daten
Kritik haben die Fachleute an einem weiteren Aspekt: In der Begründung für das Gesetz stellt das Innenministerium ADINT in Zusammenhang mit „allgemein zugänglichen Quellen“. Forscher Wetzling und Jurist Schantz finden das nicht überzeugend.
„Offenbar werden die Daten als wenig sensibel eingestuft, weil fälschlich angenommen wird, sie seien allgemein zugänglich“, schreibt Jurist Schantz in seiner Stellungnahme. Dies sei erstens nicht zutreffend, weil sie zwar käuflich seien, aber nicht frei abrufbar. Zweitens seien auch allgemein zugängliche Daten nicht per se schutzlos.
„Unverfroren“ findet das Thorsten Wetzling von Interface. Einerseits gebe es „den millionenfachen Ankauf von Datensätzen mit erstaunlich granularen personenbezogenen Daten“, andererseits offen zugängliche Infos wie Presseveröffentlichungen. Die Bundesregierung setze das gleich. ADINT stelle jedoch einen grundlegenden Paradigmenwechsel in der nachrichtendienstlichen Informationsbeschaffung dar. Dass dieser „verzwergt“, also kleingeredet werden soll, ist Wetzling zufolge „nicht vertrauensfördernd“.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Mit einem neuen Kompetenzzentrum will die Bundesagentur für Arbeit effizienter „organisierten Leistungsmissbrauch“ aufdecken. Fachleute zweifeln, ob das Problem existiert, und befürchten: Insbesondere rassistisch diskriminierte Menschen könnten so ins Visier geraten und nicht die Leistungen bekommen, die ihnen zustehen.

„Wir vergleichen das Jobcenter mit einem Taschenspieler, immer fehlt ein bißchen was im Bewilligungsbescheid und verbleibt in der Tasche.“ So schildert eine Sprecherin der Berliner Erwerbsloseninitiative BASTA! auf Anfrage von netzpolitik.org ihre Erfahrungen. Mal sei es die korrekte Miethöhe, mal der Regelbedarf für eine Person im Haushalt, mal das Geld für Bildung und Teilhabe, mal die Kosten für die Reparatur der Brille. Ein anderes Mal finde überhaupt keine Antragsbearbeitung statt.
Die Initiative BASTA! berät und unterstützt Menschen, die Bürgergeld erhalten, bei Klagen. „Es sind wirklich viele Gelder, die erst gar nicht zur Auszahlung kommen“, berichtet die Sprecherin. „Gerade bei Menschen aus Osteuropa kommt das Geld nicht in gesetzlich geregelter Höhe an.“ Dass Menschen trotz ihres Rechtsanspruchs Leistungen verweigert werden, fürchtet BASTA!, könnte sich bald noch weiter verschlimmern. Der Grund: das neue Kompetenzzentrum Leistungsmissbrauch.
Die kürzliche Reform des Bürgergelds zum Grundsicherungsgeld, die am 1. Juli weitgehend in Kraft getreten ist, sah nämlich neue und erweiterte Aufgaben zur Bekämpfung des „organisierten Leistungsmissbrauchs“ für die Bundesagentur für Arbeit (BA) vor. Dafür hat das neue zentrale „Kompetenzzentrum Leistungsmissbrauch“ in Nürnberg am Monatsanfang seine Arbeit aufgenommen. Es soll die bisherigen Ressourcen bündeln und dadurch noch effizienter gegen „organisierten Leistungsmissbrauch“ vorgehen – durch präventive, analytische und koordinierende Maßnahmen soll es diesen bekämpfen.
Ganze 72 Mitarbeiter*innen soll die zentrale Einheit in Nürnberg beschäftigen. Im ersten Halbjahr 2027 sollen fünf weitere regionale Zentren dazukommen. Ihre zukünftigen Standorte stehen noch nicht abschließend fest.
Alle sechs Zentren zusammen sollen mehr als 10 Millionen Euro jährlich kosten. Diesen Kosten sollen jedoch „Einsparungen in etwa dreifacher Höhe gegenüberstehen“, heißt es im Bericht des zuständigen Bundestagsausschusses für Arbeit und Soziales. Diese Schätzung beruht auf zwei laufenden Pilotprojekten in NRW und Berlin.
Laut Vanessa Ahuja, der zuständigen Vorständin bei der Bundesagentur für Arbeit, treten „kriminelle, organisierte Strukturen nicht massenhaft, aber auch nicht nur in Einzelfällen auf“ und sind „ausdrücklich nicht auf bestimmte Gruppen begrenzt“. Die Datenlage, die auf solche vermeintlichen organisierten Strukturen hinweist, ist jedoch mehr als dünn.
Gibt es überhaupt ein Problem mit organisiertem Leistungsmissbrauch?
„Organisierter Leistungsmissbrauch“ – die Arbeitsagentur spricht von „bandenmäßigem“ Missbrauch – besteht laut der Behörde etwa darin, dass EU-Bürger*innen nach Deutschland kommen, ihre Arbeitsverträge oder ihre Selbständigkeit vortäuschen, um dann aufstockende Leistungen zu erhalten. Sie würden von Kriminellen nach Deutschland gelockt, die im Hintergrund agieren und die gezahlten Leistungen für sich einbehalten.
Die Daten zu Verfahren wegen Verdachts auf „bandenmäßigen“ Betrug liegen nur aus den 300 Jobcentern vor, die von der Bundesagentur für Arbeit und den Kommunen gemeinsam betrieben werden. Daten aus den 104 rein kommunal organisierten Jobcentern fehlen hierzu. Auch kann die Dunkelziffer – wie so häufig – höher sein. Dennoch sprechen die Zahlen eine deutliche Sprache.
Vergangenes Jahr haben die Jobcenter 430 Verfahren eröffnet. In rund drei Viertel der Fälle haben sie eine Strafanzeige gestellt. Im Jahr davor gab es ähnlich viele eröffnete Verfahren, in rund der Hälfte der Fälle kam es zu einer Strafanzeige. Wie die Strafverfolgungsbehörden mit den Anzeigen weiterverfahren, bleibt häufig unklar. Den Ausgang teilen sie den Jobcentern nicht immer mit.
Für das Jahr 2025 weiß die Arbeitsagentur in 39 Fällen, was aus den Anzeigen wurde. In 10 von ihnen gab es eine Verurteilung zu einer Geldstrafe. Im Jahr 2024 kam es bei 36 Fällen mit bekanntem Ausgang zu 3 Verurteilungen zu Geldstrafen. Im Jahr 2023 kam es zu 6 Verurteilungen zu Geldstrafen bei 44 Fällen mit bekanntem Ausgang. Selbst in diesen Fällen waren die Gerichte offenbar nicht überzeugt, dass es sich tatsächlich um „bandenmäßigen“ Betrug handelte. Für diesen Straftatbestand sieht das Strafgesetzbuch nämlich eine Freiheitsstrafe vor – in minder schweren Fällen ab sechs Monaten.
Zum Vergleich: Zuletzt bezogen rund 5,2 Millionen Menschen Bürgergeld. Verfahren wegen „bandenmäßigen Leistungsmissbrauchs“ eröffnen die Jobcenter nur bei nicht-deutschen Unionsbürger*innen. Alle anderen Fälle, die im Zusammenhang mit organisierten Tätergruppen stehen, werden nicht separat als bandenmäßiger Leistungsmissbrauch erfasst.
Beim Arbeitslosengeld ist von „organisiertem Leistungsmissbrauch“ etwa die Rede, wenn eine Firma Menschen einstellt, ihnen fiktiv Lohn zahlt und sie dann nach Ablauf von 12 Monaten arbeitslos meldet. Hier liegen die Zahlen in einem noch niedrigeren zweistelligen Bereich. Die Bundesagentur gibt an, dass die Agenturen für Arbeit im vergangenen Jahr lediglich zehn Fälle „bandenmäßigen“ Betrugs zur Anzeige gebracht und sechs an den Zoll abgegeben haben. Zum Ausgang dieser Verfahren liegen der Behörde keine Daten vor. Auch hier zum Vergleich: Etwa eine Million Menschen bezog zuletzt Arbeitslosengeld.
Gegen Ausweiskontrollen im Netz.
Wir kämpfen für ein offenes Internet. Mit deiner Unterstützung.
Nicht umsonst haben zahlreiche Expert*innen und Verbände darauf hingewiesen, dass es in der Debatte um Leistungsmissbrauch an Fakten mangele und die Diskussion extrem unverhältnismäßig und diffamierend geführt werde. Beispielsweise haben im Herbst 60 Organisationen die öffentliche Debatte scharf verurteilt. Sie stigmatisiere armutsbetroffene Menschen und blende strukturelle Ursachen wie Ausbeutung, unsichere Beschäftigung und fehlenden Schutz von Arbeitsmigrant*innen aus.
Wo in den Daten steckt „organisierter Leistungsmissbrauch“?
Mit Hilfe von strukturellen und einzellfallunabhängigen Datenanalysen soll das neue Kompetenzzentren Auffälligkeiten finden, die auf „organisierten Leistungsmissbrauch“ hinweisen. So seien etwa „eine gehäufte zeitgleiche Anmeldung von Mitarbeitern einer Firma, auffällige Fluktuation oder die Anmeldung von übermäßig vielen Personen an einer Wohnadresse“ Hinweise solcher Art, teilte die Sprecherin der Bundesarbeitsagentur auf Anfrage mit.
Wie genau das Zentrum die Daten analysieren und auf solche „Auffälligkeiten“ stoßen will, möchte die Arbeitsagentur nicht offenlegen. „Die konkreten Prüfmechanismen, wie Leistungsmissbrauch aufgedeckt wird, werden im Detail nicht veröffentlicht“, so die Sprecherin. „Es werden die bereits bestehenden IT-Verfahren der BA genutzt.“
Bisher war für solche Analysen der sogenannte Fachbereich „Enterprise Fraud Management“ der Zentrale der BA zuständig. Dieser analysiert monatlich Auszahlungsdaten der BA, um zeitgleiche, doppelte Auszahlungen von Leistungen zu identifizieren. Hegen die Datenanalyst*innen den Verdacht, dass etwa Arbeitsbescheinigungen manipuliert oder Arbeitsverhältnisse fingiert sind, führen sie durch gezielte Abfragen im Datenbestand anlassbezogene „Plausibilisierungen“ durch. Wie aus einem geleakten Dokument hervorgeht, dessen erste Version im Jahr 2019 an die Öffentlichkeit gelang, stellt diese Abteilung die Ergebnisse ihrer Analysen in einer sogenannten Heatmap zusammen und verschickt sie an die jeweiligen Jobcenter.
Bei dieser Heatmap handelt es sich um eine aus der Polizeiarbeit entlehnte Methode der „Mustererkennung“, mit der sich die Daten von bestimmten Leistungsbeziehenden etwa nach „Adressen, Arbeitgebern, über mehrere Leistungsfälle hinweg genutzten Telefonnummern oder Zahlungsverbindungen“ sortieren und anzeigen lassen. Die Jobcenter sollen dann die Heatmaps nutzen, um „Auffälligkeiten zu entdecken“ und weitere Ermittlungen vor Ort durchzuführen.
Ganze Bevölkerungsgruppen unter Generalverdacht
Nicht alle Leistungsbeziehenden werden auf möglichen Leistungsmissbrauch durch den Fachbereich durchleuchtet. Offenbar wird es beim Kompetenzzentrum Leistungsmissbrauch auch so bleiben. „Die Datenanalyse wird sich ausschließlich auf ausgewählte Fallkonstellationen, Gruppen oder Risikohinweise begrenzen“, sagte die Sprecherin der BA gegenüber netzpolitik.org.
So berichtet beispielsweise die Leiterin eines Jobcenters, die in einer Ende 2025 veröffentlichten Studie zitiert wird, dass ihrem Jobcenter mit der Heatmap „Adressen von 200 Rumänen zur Verfügung gestellt“ wurden. Sie beschreibt, dass Heatmaps soziale Netzwerke widerspiegeln sollen, bei denen die Häufung von Leistungsbeziehenden an einem bestimmten Ort als Hinweis auf „organisierten Leistungsmissbrauch“ gilt. Nach näherer Überprüfung stellte sich heraus, dass der Verdacht unbegründet war.
Welche Gruppen beim Verdacht des „organisierten Missbrauchs“ im Visier der BA stehen, geht ebenfalls aus der bereits erwähnten geleakten Arbeitshilfe „Bekämpfung von bandenmäßigem Leistungsmissbrauch im spezifischen Zusammenhang mit der EU-Freizügigkeit“ hervor. Beratungsstellen und Verbände wie der Erwerbslosen- und Sozialhilfeverein Tacheles e. V. und das Netzwerk Europa in Bewegung kritisierten nach der Veröffentlichung, dass diese Arbeitshilfe rassistische und Rom*nja-feindliche Zuschreibungen reproduziere und insbesondere Menschen aus Rumänien und Bulgarien unter Generalverdacht des „organisierten Leistungsmissbrauchs“ stelle.
Organisierter Leistungsmissbrauch oder institutioneller Rassismus?
Eine Beweisführung, dass diese Menschen tatsächlich „organisierten Leistungsmissbrauch“ begehen, fehle im Dokument vollkommen, so die Kritik weiter. Die darin genannten „Tatmuster“ und „Erkennungsmerkmale“ – etwa das Fehlen eines schriftlichen Arbeitsvertrags, einer Anmeldung des Betriebs bei einem Unfallversicherungsträger oder eine kurzfristige Kündigung des Arbeitsverhältnisses – seien keine Indizien für „bandenmäßigen Leistungsmissbrauch“, sondern sprächen vielmehr für „das Vorliegen einer tatsächlichen, echten – aber prekären, ungeschützten, unsicheren und ausbeuterischen Beschäftigung“. Die Arbeitshilfe deute die eigentlichen Opfer zu Täter*innen um.
Die Bundesagentur für Arbeit hat die Arbeitshilfe nach den Protesten der Verbände etwas entschärft und nennt in späteren Fassungen keine konkreten Nationalitäten und ethnischen Gruppen mehr. Trotzdem kommt beispielsweise die Berliner Ombudsstelle gegen Diskriminierung zu der Einschätzung, dass die Arbeitshilfe Rom*nja-feindliche Diskriminierung bewirkt und gegen das Grundgesetz verstößt.
Während die BA darin nun „ausdrücklich darauf hinweist, dass EU-Bürger nicht unter Generalverdacht stehen, Leistungsmissbrauch zu begehen“, entfaltet die Arbeitshilfe in der behördlichen Praxis eben diese Wirkung. Zu diesem Schluss kommen auch Sozialwissenschaftler*innen in einer Studie von Ende 2025, die die Antidiskriminierungsstelle des Bundes in Auftrag gegeben hat. Zuschreibungen des „Sozialmissbrauchs“ würden häufig mit Bezug auf Menschen aus dem südöstlichen Europa artikuliert und insbesondere Rom*nja „virulenten Verdachtsmomenten“ ausgesetzt. Dabei handle es sich nicht nur um persönliche Vorurteile einzelner Mitarbeitender, sondern um rassistische institutionalisierte Praktiken. Das digitale Verfahren der Heatmap sei ein Ausdruck hiervon.
„Gefahr, stereotype Zuschreibungen zu institutionalisieren“
Verbände und Beratungsstellen weisen seit Jahren auf eine besonders restriktive Behandlung von Unionsbürger*innen in Jobcentern hin. In vielen Fällen werden die Leistungen trotz eines Anspruchs verweigert. Insbesondere Rom*nja oder Menschen, die als solche wahrgenommen werden, sind schon jetzt mit systematischen und rechtswidrigen Schwierigkeiten bei der Beantragung von Sozialleistungen konfrontiert. „Wir erleben dies beispielsweise derzeit bei ukrainischen Roma“, schreibt Roma Antidiscrimination Network (RAN) an netzpolitik.org. RAN ist ist ein bundesweites Netzwerk gegen Rassismus und Diskriminierung von Rom*nja, das an der Organisation Roma Center e. V. angesiedelt ist. „Immer wieder wird ihnen unterstellt, sie seien keine ukrainischen Staatsangehörigen, obwohl entsprechende Dokumente vorliegen.“ Dies führe zu verzögerter Leistungsgewährung, zusätzlichen Nachweispflichten und erheblichen Unsicherheiten.
Alles netzpolitisch Relevante
Drei Mal pro Woche als Newsletter in deiner Inbox.
Auch das Roma Antidiscrimination Network weist auf die Gefahr hin, bereits bestehende stereotype Zuschreibungen weiter zu institutionalisieren. „Deutschland hat sich aus den Erfahrungen der nationalsozialistischen Verfolgung bewusst gegen die Erfassung ethnischer Zugehörigkeit entschieden“, so das Netzwerk. „Auch wenn formell keine ethnischen Daten erhoben werden dürfen, besteht die Gefahr, dass über Nationalität, Wohnort, Namen oder bestimmte Sozialdaten faktisch ethnische Profile entstehen.“
„Präventive Datenanalysen sehen wir besonders kritisch“
Laut dem neuem Gesetz soll die Bundesagentur für Arbeit nun insbesondere auch präventiv wirksam werden und Leistungsmissbrauch verhindern, noch bevor er entsteht. Das kann bedeuten, dass das Kompetenzzentrum die Angaben „bereits bei Antragstellung“ auf Unstimmigkeiten prüft, erklärt die Sprecherin der Arbeitsagentur. Beispielsweise kann das eine Prüfung auf zeitgleiche Leistungsbezüge über Rechtskreise oder Kreisgrenzen hinweg sein. Die regionalen Zentren sollen die Auffälligkeiten dann einer vertieften Sachverhaltsaufklärung unterziehen.
Gerade vor dem Hintergrund der nationalsozialistischen Verfolgung von Rom*nja und Sinti*zze bewertet das Roma Center den Ausbau präventiver Datenanalysen und die enge Zusammenarbeit von Sozialbehörden mit Strafverfolgungsbehörden kritisch. Staatliche Stellen seien dazu verpflichtet, jede Form von Datensammlung, Datenverknüpfung und Zusammenarbeit zwischen Sozial- und Strafverfolgungsbehörden besonders streng an Grundrechten, Diskriminierungsschutz und dem Schutz vor rassistischer Profilbildung auszurichten“, schreibt das Roma Center in einer Pressemitteilung.
Zudem zeigten Erfahrungen aus mehreren nordrhein-westfälischen Kommunen, dass ein repressiver Ansatz gegen sogenannte Problemimmobilien oder vermeintlichen Leistungsmissbrauch soziale Probleme nicht löst. „Trotz jahrelanger Taskforces, Kontrollen und Räumungen sind weder Ausbeutung noch Armut verschwunden“, kritisiert RAN gegenüber netzpolitik.org. Stattdessen würden die betroffenen Menschen verdrängt und sie verlieren ihre Wohnungen, ihre Arbeitsplätze und die Anbindung an Schulen oder soziale Hilfen. Die eigentlichen Profiteure der Ausbeutung blieben dagegen unbehelligt. „Aus unserer Sicht sollte diese Bilanz Anlass sein, neue Kontrollstrukturen kritisch zu hinterfragen, anstatt sie auf Bundesebene auszuweiten“, fügt RAN hinzu.
Der Beauftragte der Bundesregierung gegen Antiziganismus und CDU-Politiker Michael Brand, zeigt sich hingegen gelassen: „Einer Institution, die ihre Arbeit noch nicht begonnen hat und die sich aufgrund von massenhaft festgestelltem Leistungsmissbrauch unserer Sozialsysteme auf die Bekämpfung dieses Leistungsmissbrauchs fokussiert, implizit vorab bereits das Risiko von Rassismus zur unterstellen, ist nicht die Haltung der Bundesregierung, auch nicht die des Beauftragten“, sagte er auf Anfrage von netzpolitik.org.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die EU-Kommission will bald einen Gesetzentwurf für ein europäisches „Mindestalter“ vorlegen. Doch während die Frage nach dem „Ob“ von Alterskontrollen politisch entschieden scheint, ist die Frage nach dem grundrechtskompatiblen „Wie“ längst nicht beantwortet. Dabei gäbe es ganz andere Möglichkeiten, das Netz zu einem besseren Ort zu machen.

Der DSC-Beirat ist ein Gremium aus Zivilgesellschaft, Forschung und Wirtschaft. Er soll in Deutschland die Durchsetzung des Digital Services Act begleiten und den zuständigen Digital Services Coordinator unterstützen. Svea Windwehr ist Mitglied des Beirats und berichtet in dieser Kolumne regelmäßig aus den Sitzungen.
Es ist ein Sommer der Rekordtemperaturen in Europa und auch digitalpolitisch geht es heiß her. Auf die Schnelle und ohne Rücksicht auf grundrechtliche Verluste hat die schwarz-rote Koalition die IP-Vorratsdatenspeicherung durch die erste Lesung im Bundestag gejagt, einen Frontalangriff auf das Informationsfreiheitsgesetz gestartet und ist nicht nur dabei, mit dem sogenannten Sicherheitspaket die biometrische Auswertung des gesamten Internets zu beschließen, sondern hat – spontan – auch noch neue Befugnisse für die Bundespolizei eingeführt, um Gesichtserkennung in Echtzeit zu ermöglichen.
Angesichts dieser Nachrichten wirkt die Durchsetzung des Digital Services Acts, der seit 2024 geltende Rechtsrahmen für Online-Plattformen in Europa, wie ein zu vernachlässigendes Thema. Wenn nicht auch hier Massenüberwachung und massive Probleme für die Sicherheit, Privatsphäre und das offene Netz lauern würden.
Alterskontrollen für alle
Nachdem sich eine von Bundesministerin Karin Prien eingesetzte Expert:innenkommission nicht darauf einigen konnte, welche Art von Alterskontrollen sie genau empfehlen möchte, wird die Europäische Kommission wohl bald Tatsachen schaffen. Basierend auf dem Bericht der beiden Vorsitzenden der Expert:innenkommission zum Schutz junger Menschen im Netz hat Kommissionspräsidentin Ursula von der Leyen Anfang der Woche angekündigt, einen Gesetzentwurf für ein europäisches „Mindestalter“ vorzulegen. Vorgesehen ist, dass junge Menschen unter 13 Jahren keinen Zugang zu einer breiten Palette an Diensten haben sollen. Welche Dienste genau gemeint sind, ist unklar – von der Leyen spricht von „Social Media Plus“, gemeint sein könnten also auch Angebote wie Messenger-Apps, Online-Spiele, Videoplattformen oder KI-Systeme.
Der Bericht der beiden Vorsitzenden der Expert:innenkommission zeichnet ein sehr viel differenzierteres Bild als die Social-Media-Verbote für Unter-16-Jährige, die in Australien bereits gescheitert sind und dennoch in Ländern wie Großbritannien und Dänemark vorangetrieben werden. Der Bericht spricht sich für einen gestaffelten Ansatz aus: Kleine Kinder bis 3 Jahre sollten Bildschirmen gar nicht ausgesetzt sein, 3- bis 13-Jährige sollen nur unter Aufsicht im Internet unterwegs sein, ab 13 und bis 17 sollen Dienste nur dann zugänglich sein, wenn sie kinder- beziehungsweise altersgerecht sind. Die beiden Vorsitzenden der Expert:innenkommission differenzieren also durchaus zwischen verschiedenen Altersgruppen und heben auch deutlich die Vorteile und Chancen hervor, die das Netz und Online-Räume für junge Menschen bieten können. Dennoch ist klar, dass jede Form von Alterskontrollen im Namen des Jugendschutzes Alterskontrollen für alle Nutzer:innen bedeuten. Und genau hier liegt die Krux.
Kontrolle first, Bedenken second
Der Bericht unterstreicht, dass Altersverifikationstechnologien verhältnismäßig sein müssen und Grundrechte wahren sollen, insbesondere die Rechte von Kindern. Sie sollen außerdem höchsten Anforderungen bezüglich Sicherheit und Datenschutz genügen müssen. In diesem Kontext werden sogenannte Zero Knowledge Proofs erwähnt, also kryptographische Ansätze, um zu bestätigen, dass eine Aussage wie „über 18“ wahr ist, ohne genauere Informationen wie Alter oder Identität preiszugeben. Zero Knowledge Proofs sind aber keine Pauschallösung, um sicherzustellen, dass Anbieter von Altersverifikationstechnologien nicht erfahren, welche Webseiten eine Benutzerin besucht, oder dass die Website keine weiteren Informationen über eine Benutzerin erhält. Für die Herausforderungen, die Alterskontrollen mit sich bringen, braucht es weitere Lösungen und verbindliche Schutzmechanismen.
Wie auch die deutsche Expert:innenkommission bleibt uns also auch von der Leyens Expert:innenbericht Antworten auf eine Kernfrage schuldig: Wie sollen Alterskontrollen umgesetzt werden, die die Privatsphäre und Datensicherheit aller Nutzenden schützen, sich nicht als Überwachungsinfrastruktur zweckentfremden lassen, und tatsächlich zugänglich für alle sind? Verfügbare Altersfeststellungstechnologien basieren entweder auf Ausweisdokumenten, die für viele Menschen, inklusive jüngere Teenager, nicht zugänglich sind. Hier fehlt ein alltagstaugliches Konzept, wie Menschen ohne Ausweisdokumente diskriminierungsfrei an Altersnachweise kommen sollen. Oder aber auf der Schätzung von Alter anhand biometrischer Daten oder anderer Signale, also auf der umfangreichen Verarbeitung von personenbezogenen Daten. Einerseits zeigen die Expert:innen die damit verbundenen massiven Gefahren von Alterskontrolltechnologien nicht nur für Grundrechte, sondern auch das offene und freie Internet auf, andererseits sprechen sie sich trotzdem für altersbasierte Einschränkungen aus.
Von der Leyen selbst hat sich in der Vergangenheit schon für eine Umsetzung von Alterskontrollen anhand des sogenannten „Mini-Wallets“ ausgeprochen, also jener Altersverifikationsapp, die Telekom-Tochter T‑Systems unter Einsatz von Google-Komponenten für einen mittleren Millionenbetrag gebaut hat.
Genau jene App, die nicht nur IT-Expert:innen scharf wegen ihrer Sicherheits- und Privatsphäremängel kritisiert haben, sondern auch der deutsche Ethikrat. In seiner durchaus differenzierten Stellungnahme zu „Schutz, Teilhabe und Befähigung von Kindern und Jugendlichen in der digitalen Welt“ hat sich der Rat mit Blick auf diese Mängel gegen Altersverifikation anhand der „Mini-Wallet“ ausgesprochen: „Alternativen wie die Mini-Wallet oder gar das Vorzeigen von Pass und Gesicht vor der Handykamera sind aus Gründen der Sicherheit und des Schutzes der Privatsphäre abzulehnen.“
Plattformregulierung als schärferes Schwert
Jenseits der Frage, wie Alterskontrollen einigermaßen grundrechtsschonend umgesetzt werden könnten, bleibt die Frage ihrer Wirksamkeit unterbelichtet. Wie Kinder- und Jugendschutzorganisationen, Vertretungen von Jugendlichen und sogar Aufsichtsbehörden immer wieder betonen, sind altersbasierte Beschränkungen nicht das richtige Mittel, um Plattformen tatsächlich zu Räumen zu machen, in denen Kinder und Jugendliche sich und das Netz in einem geschützten Rahmen ausprobieren können.
Hier geben Nachrichten aus Brüssel Grund zu Hoffnung: In ihrer Untersuchung von Meta ist die Europäische Kommission zu dem vorläufigen Ergebnis gekommen, dass suchtfördernde Designfeatures auf Instagram und Facebook gegen den DSA verstoßen.
Konkret geht es um genau die Features, die Menschen auf den Plattformen bleiben lassen und so zentral zu Metas Geschäftspraktiken sind: hochpersonalisierte Empfehlungen, Autoplay und endlose Feeds. Die EU-Kommission argumentiert, dass Meta nicht nur die negativen Implikationen dieser Features unzureichend analysiert und gemindert hat. Sondern der Konzern habe auch ihm vorliegende Informationen dazu ignoriert, wie Kinder und Jugendliche mit diesen Features interagieren. Die Schlussfolgerung der Kommission: Diese Features müssen abgeschaltet werden.
Ob es tatsächlich so weit kommt, wird sich in den nächsten Phasen der Untersuchung zeigen. Fest steht aber, dass der DSA Chancen bietet, mehr als nur die Symptome von problematischen Geschäftspraktiken zu bekämpfen. Wo Alterskontrollen das Risiko bergen, das Internet für alle unsicherer zu machen, könnte der DSA genutzt werden, um diejenigen in die Verantwortung zu ziehen, die für den Status Quo verantwortlich sind. Und wie der Fall von X zeigt, wirkt die Arbeit der Europäischen Kommission: Am Mittwoch wurde bekannt gegeben, dass X Forderungen der EU-Kommission zugestimmt hat, um den Anforderungen des DSA gerecht zu werden. Wenn also sogar Elon Musk dazu gebracht werden kann, europäischer Regulierung zu folgen, beweist das: Der DSA wirkt. Auch große US-Plattformen können durch konsequente Durchsetzungsarbeit in ihre Schranken gewiesen werden, ohne dass die Rechte ihrer Nutzenden massiv eingeschränkt werden müssen.
Die nächsten Wochen werden zeigen, wie die Europäische Kommission mit den Empfehlungen aus dem Expert:innenbericht umgehen wird. Zu befürchten sind Alterskontrollen für große Teile des Internets. Zu gewinnen gäbe es dagegen die Chance, einen tatsächlich wirksamen Weg für ein besseres Internet für alle einzuschlagen – besonders auch für junge Menschen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.